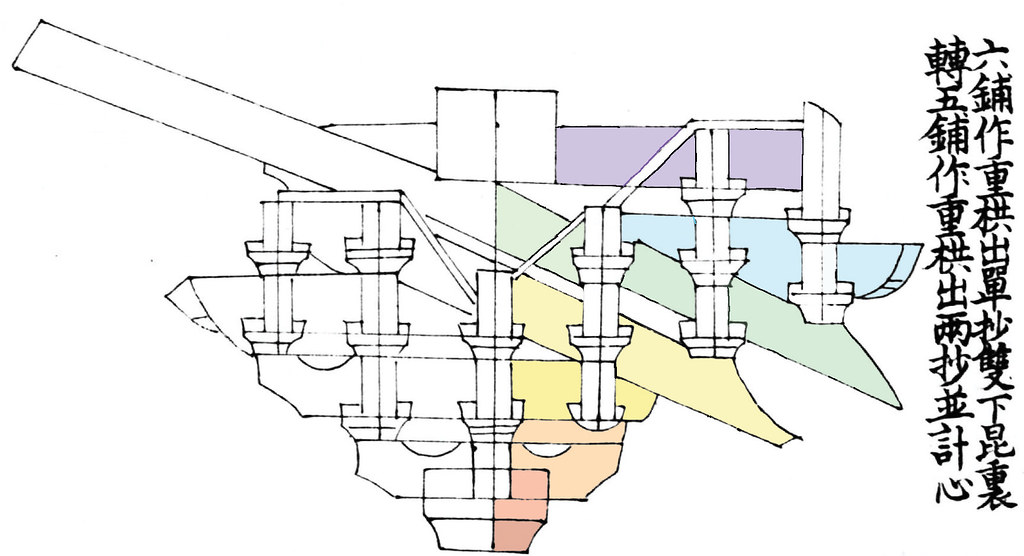
完整版参见 https://blog.v2beach.cn/2024/09/24/cs231n-1/ 。
V2beach
行年五十而知四十九年非。
Hangzhou, China
文章
89
分类
3
标签
79
technology
Update your browser to view this website correctly. Update my browser now
×