Data parallelism is a way to process multiple data batches across multiple devices simultaneously to achieve better performance. In PyTorch, the DistributedSampler ensures each device gets a non-overlapping input batch. The model is replicated on all the devices; each replica calculates gradients and simultaneously synchronizes with the others using the ring all-reduce algorithm(梯度在設備間環狀傳遞、求和、更新).
DataParallel(DP) vs. Distributed Data Parallel(DDP)
| DataParallel | DistributedDataParallel |
|---|---|
| More overhead; model is replicated and destroyed at each forward pass | Model is replicated only once |
| Only supports single-node parallelism | Supports scaling to multiple machines |
| Slower; uses multithreading on a single process and runs into Global Interpreter Lock (GIL) contention | Faster (no GIL contention) because it uses multiprocessing |
| 特性 | Multithreading (多线程) | Multiprocessing (多进程) |
|---|---|---|
| 适用场景 | I/O密集型任务(如文件操作、网络请求等) | CPU密集型任务(如科学计算、数据处理等) |
| 执行方式 | 线程共享同一内存空间,多线程在同一进程内执行 | 每个进程拥有独立内存空间,多个进程并行执行 |
| 性能 | 由于 GIL,不能真正并行执行 CPU 密集型任务 | 能充分利用多核 CPU,适合 CPU 密集型任务 |
| 内存开销 | 内存共享,开销较小 | 每个进程拥有独立内存,内存消耗较大 |
| 创建和销毁开销 | 线程较轻量,创建和销毁开销较小 | 进程较重,创建和销毁的开销较大 |
| 进程/线程间通信 | 线程间共享内存,通信高效但可能存在线程安全问题 | 进程间需要使用 IPC(如队列、管道),通信较复杂 |
| 调试难度 | 难度较大,尤其是在多线程竞争和死锁问题上 | 相对较简单,进程独立,错误隔离更好 |
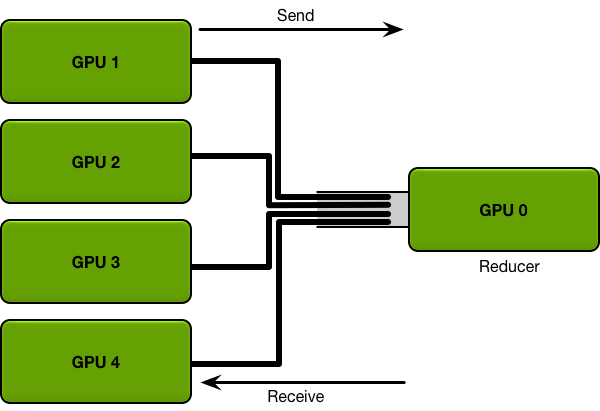
Ring-Allreduce
每个设备上都会存完整的model用于前向计算,但是会把batch拆成batch_size除以设备数的batches,然后反向传播得到的梯度dW靠All Reduce传递计算dW的平均值来更新model weights。
https://andrew.gibiansky.com/blog/machine-learning/baidu-allreduce/
上面這邊博客比PyTorch DDP官方教程裡提供的這篇講得清楚很多。
算法名
所謂Ring是指將GPU構成邏輯環,每個GPU只跟兩個GPUs連接,一個left neighbour一個right neighbour,chunk只會從左邊接收發給右邊。
所謂Allreduce是指相比1個reducer而言,所有的GPUs都作為聚合者reducer。
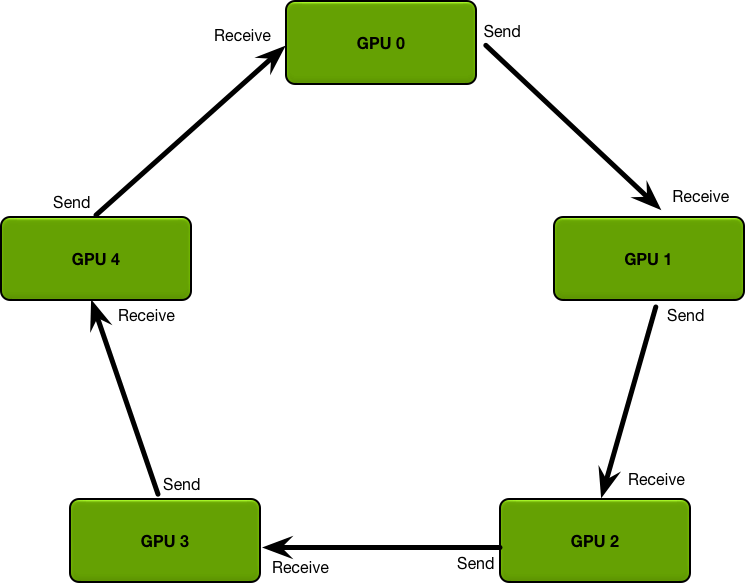
算法
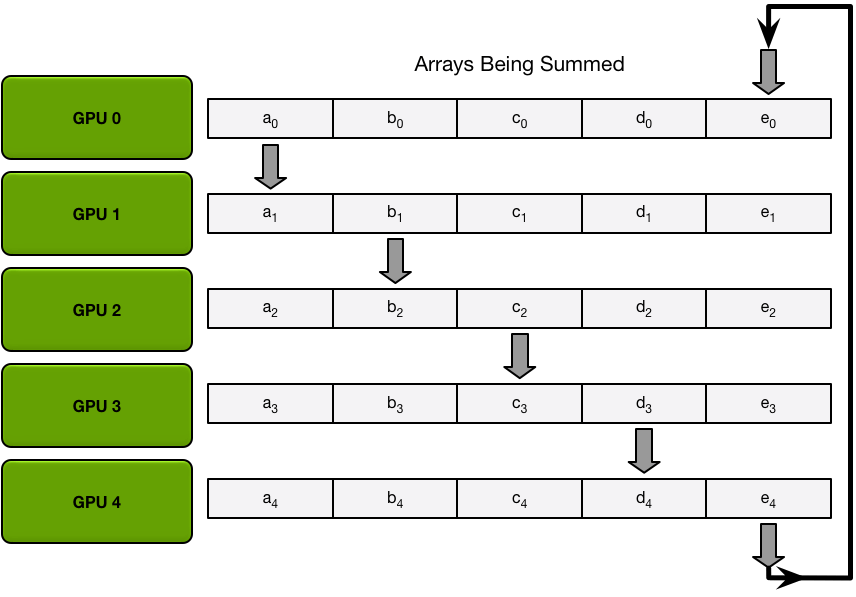
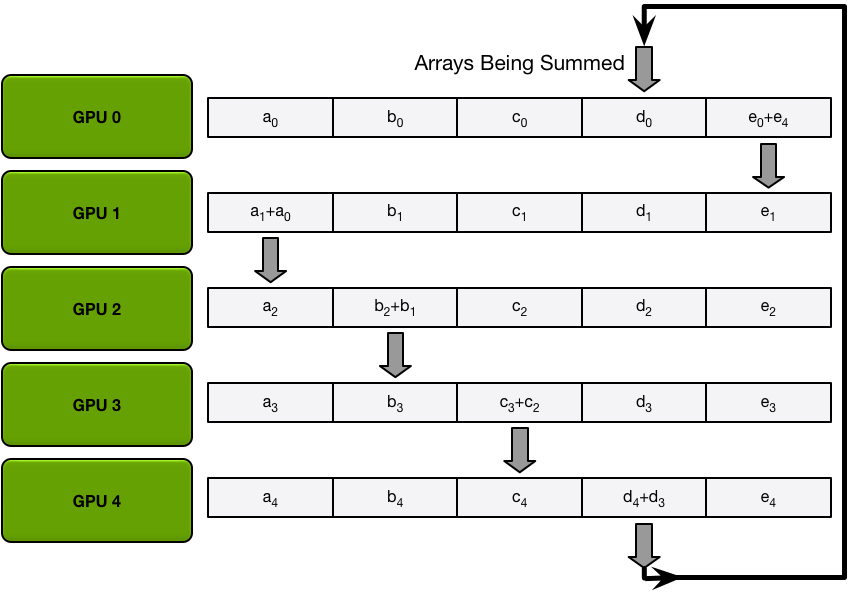
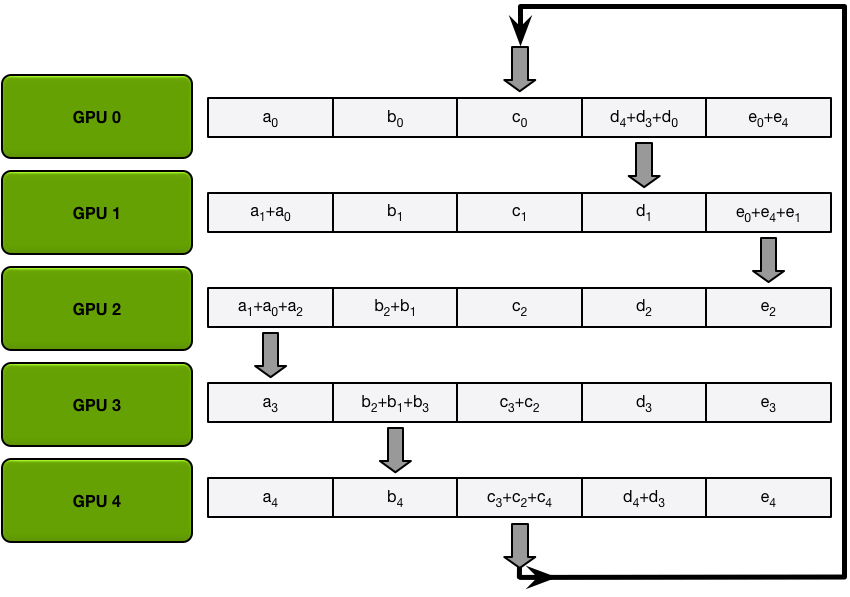
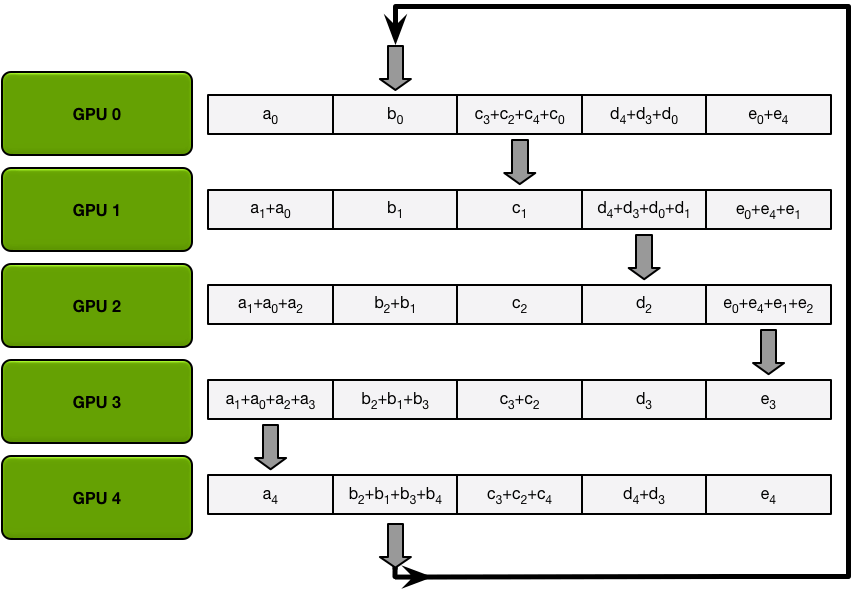
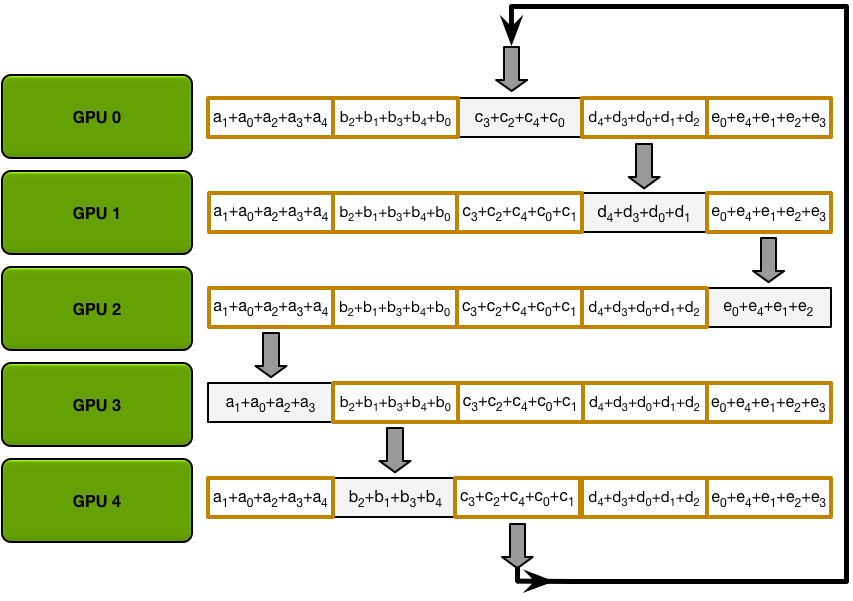
Ring-Allreduce以計算一個求和任務為例(exactly what we need in backprop),有Scatter Reduce-Allgather兩個階段:
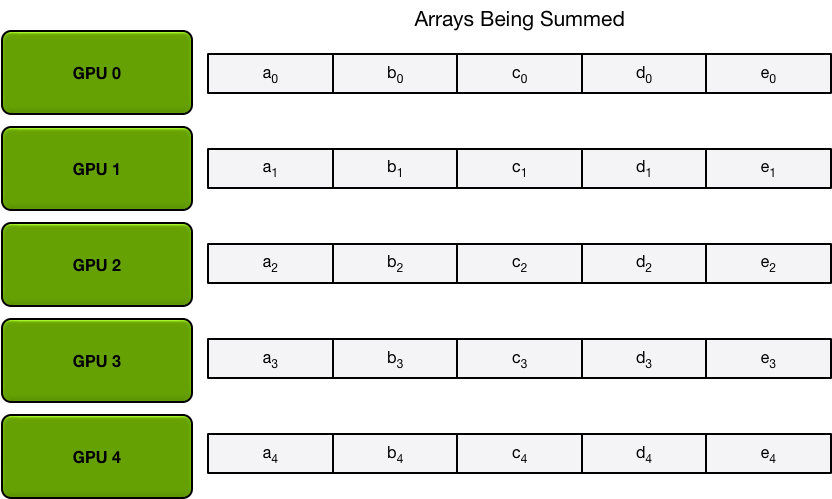
- 首先假如有5個GPUs,所有GPU上的array就都被分成5個chunks。
- Scatter Reduce 階段每個第 N 個 GPU 都會發生 N-1 個 iterations,每次迭代的操作是求和:
- 1st iteration 發送第 n 個 chunk,接收第 n-1 個 chunk;
- 之後的所有 iterations 裡都是發送剛接收到的 chunk。
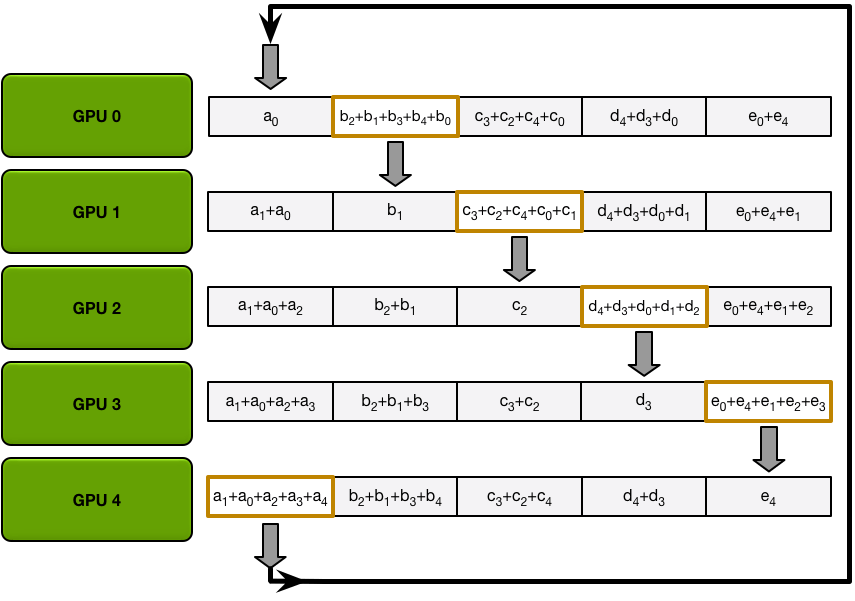
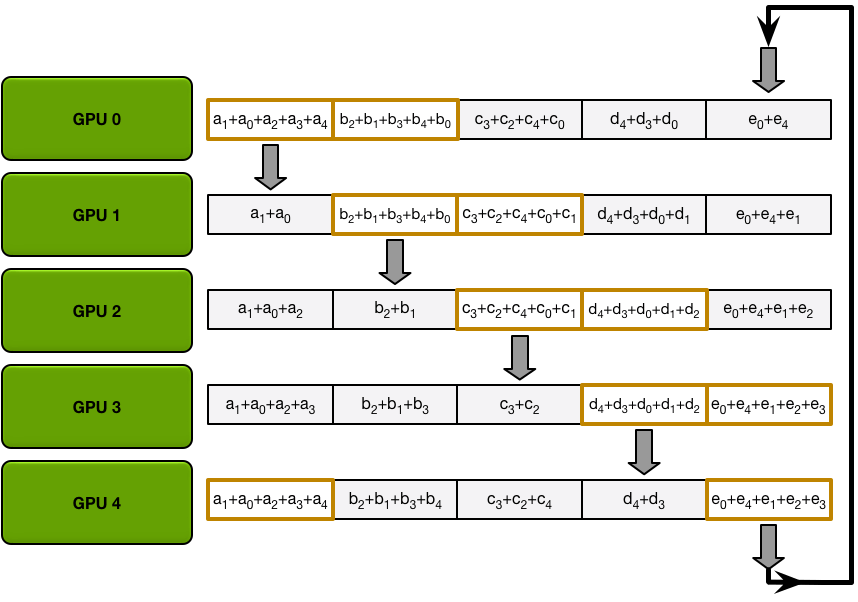
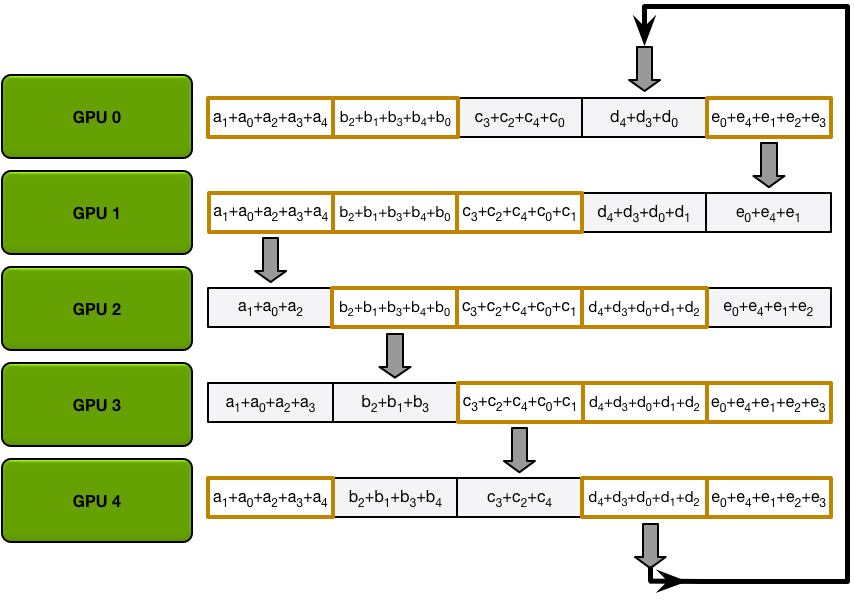
- Allgather 階段每個第 N 個 GPU 也都會發生 N-1 個 iterations,每次迭代只是用接收的 chunk 覆蓋原本 chunk:
- 1st iteration 發送第 n+1 個 chunk,接收第 n 個 chunk;
- 之後的所有 iterations 裡都是發送剛接收到的 chunk。(同上)
| Scatter-reduce data transfers (iteration 1) | Scatter-reduce data transfers (iteration 2) | Scatter-reduce data transfers (iteration 3) | Scatter-reduce data transfers (iteration 4) | Final state after all scatter-reduce transfers |
|---|---|---|---|---|
 |
 |
 |
 |
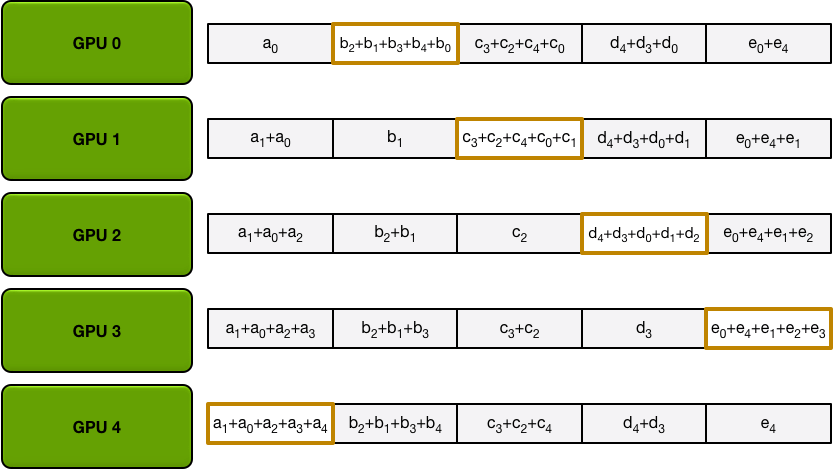 |
每個 GPU 上有一個求和結束的 chunk,每個 GPU 都作為 reducer 完成了工作。
| Allgather data transfers (iteration 1) | Allgather data transfers (iteration 2) | Allgather data transfers (iteration 3) | Allgather data transfers (iteration 4) | Final state after all allgather transfers |
|---|---|---|---|---|
 |
 |
 |
 |
 |
Bandwidth vs. Latency:
Bandwidth帶寬是每秒通過A點的數據量;
Latency延遲是一個數據從A點到B點需要的時間。
帶寬遠大於延遲時 Ring-Allreduce 這種與 GPU 數量無關的算法會很快,上面第一種方法因為壓力會給到帶寬(reducer要挨個給每個GPU返回幾個G的梯度數據更新參數)所以耗時跟 GPU 數量是線性增長關係。
MapReduce的reduce
reduce算法中reduce的意思不是減少,而是“合併”(併是動詞,並是其他副詞連詞詞性)、“聚合”。
假如用MapReduce算法做統計文本的單詞頻率這個任務,以“hello world hello”為例,有Map-Shuffle-Reduce三個階段:
- Map:文本分割成單詞,構造鍵值對。
("hello", 1)
("world", 1)
("hello", 1) - Shuffle:Map的輸出會經過Shuffle把Key一樣的值聚集到一起。
("hello", [1, 1])
("world", [1]) - Reduce:對Shuffle的結果聚合,這個任務是求和,有的任務是統計Key出現的次數,有的是求Value最大最小值,有的是把Value合併成一個數據結構。
("hello", 2)
("world", 1)
DDP
- 構建 Process Group(進程組,DDP是multiprocessing,DP是multithreading),其中backend有两种,用于支持多设备之间通信操作比如广播(Broadcast)聚合(Reduce)和All-Reduce等,NCCL全称是NVIDIA Collective Communications Library针对多GPU场景,Gloo是Facebook AI Research开发的针对CPU和GPU混合场景。
def ddp_setup(rank: int, world_size: int):
"""
Args:
rank: Unique identifier of each process
world_size: Total number of processes
"""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12355"
torch.cuda.set_device(rank) # sets the default GPU for each process.
# 分佈式進程組 distributed process group 包含mp.spawn出來的所有能交流和同步的進程
torch.distributed.init_process_group(backend="nccl", rank=rank, world_size=world_size) # 默認用 TCP 協議初始化 distributed process group,backend 的選擇上,GPU分佈式訓練用NCCL,CPU分佈式訓練用Gloo - 構建 DDP model。
self.model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[gpu_id])
- Distributing Input Data(分發輸入數據)。
train_data = torch.utils.data.DataLoader(
dataset=train_dataset,
batch_size=32,
shuffle=False, # We don't shuffle
sampler=torch.utils.data.distributed.DistributedSampler(train_dataset), # 為所有 distributed process 隨機採樣不重複的數據,GPUs/Processe 之間不重複,共有 32 * nprocs 個有效 samples,如果用 torch.distributed,DistributedSampler 會自動獲取 rank 所以不用顯式指定?
)
def _run_epoch(self, epoch):
b_sz = len(next(iter(self.train_data))[0])
self.train_data.sampler.set_epoch(epoch) # 每個 epoch 重新打亂一次,否則每個 epoch 隨機抽樣順序一樣每個 process 可能拿到同樣的數據
for source, targets in self.train_data:
...
self._run_batch(source, targets) - 保存模型 checkpoints。
- ckp = self.model.state_dict()
+ ckp = self.model.module.state_dict()
...
...
- if epoch % self.save_every == 0:
+ if self.gpu_id == 0 and epoch % self.save_every == 0: # 只有rank0主進程保存ckp,因為根據上面的ring-allreduce算法每個gpu上的參數相同,集合調用 Collective calls 要在這之前是什麼意思?
self._save_checkpoint(epoch) - 運行分佈式訓練(distributed training),torch.multiprocessing是對原生multiprocessing封裝的wrapper。
- def main(device, total_epochs, save_every):
+ def main(rank, world_size, total_epochs, save_every):
+ ddp_setup(rank, world_size)
dataset, model, optimizer = load_train_objs()
train_data = prepare_dataloader(dataset, batch_size=32)
- trainer = Trainer(model, train_data, optimizer, device, save_every)
+ trainer = Trainer(model, train_data, optimizer, rank, save_every) # 原來是 device,現在是 rank
trainer.train(total_epochs)
+ torch.distributed.destroy_process_group() # 結束訓練要釋放 process group
if __name__ == "__main__":
import sys
total_epochs = int(sys.argv[1])
save_every = int(sys.argv[2])
- device = 0 # shorthand for cuda:0
- main(device, total_epochs, save_every)
+ world_size = torch.cuda.device_count() # world_size 不一定等於 gpus 數?
+ torch.multiprocessing.spawn(main, args=(world_size, total_epochs, save_every,), nprocs=world_size) # mp.spawn 調用時會由 DDP 自動分配 rank 給 process
计算模型显存占用量?