Gym 是 OpenAI 做的 RL tasks 模拟库 (虽然 Play Atari w/ Deep RL 等都是 Deepmind 发的),比如 CartPole, Robot Locomotion, Atari 2600 都有模拟。除了 Python 外在 C++ 也实现了此 API。
其中 ALE (Arcade-Learning-Environment) 是 Atari 2600 part,stable-baselines3 在这个模拟库的逻辑之上实现 RL 经典算法。
Gymnasium
為所有單 Agent RL Environments 提供 API,並實現了一些常用環境。
Env
Env 是 Gym 的核心,是個實現了 Markov 決策過程的類,能生成 initial state、給定 action 转移到下一个 state、可视化 environment。Wrapper 用来修改 environment,即修改 agent observations, rewards, actions。
使用 Gym 有四个关键函数 make(), Env.reset(), Env.step(), Env.render()。
初始化环境
import gymnasium as gym |
make() 返回一个可交互的 Env 对象,pprint_registry() 查看所有可以创建的环境。
可以指定 environment 内部定义的 render_mode,可以为 None, 字符串比如 human, rgb_array, rgb_array_list 等,以 rgb_array 和 rgb_array_list 为例:
frame = env.render(render_mode='rgb_array') # 返回单个图像帧 (3 维 numpy 数组) |
用 register 初始化的话, 可以用gym.register(id="namespace/mandatory name-optional version", entry_point=class)
最好用 register 更灵活的扩展 register_envs,比如 gym.register(ale_py) 这种语法在 register 里不行。
gymnasium.pprint_registry() 能打印所有注册的环境,注册过才可以用 gymnasium.make() 创建,gymnasium.make_vec(, num_envs=n) 可以生成 n 个并行的相同环境。
环境交互
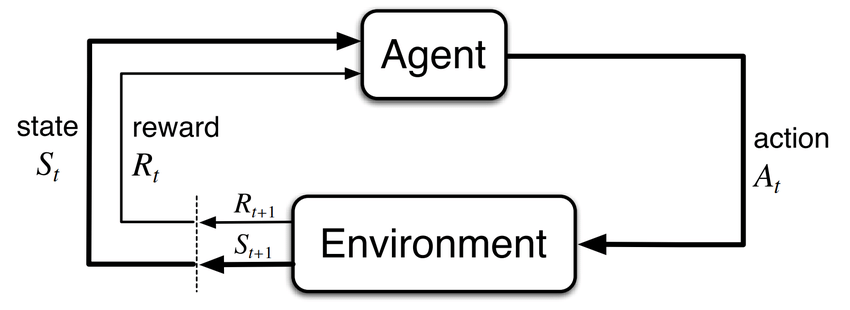
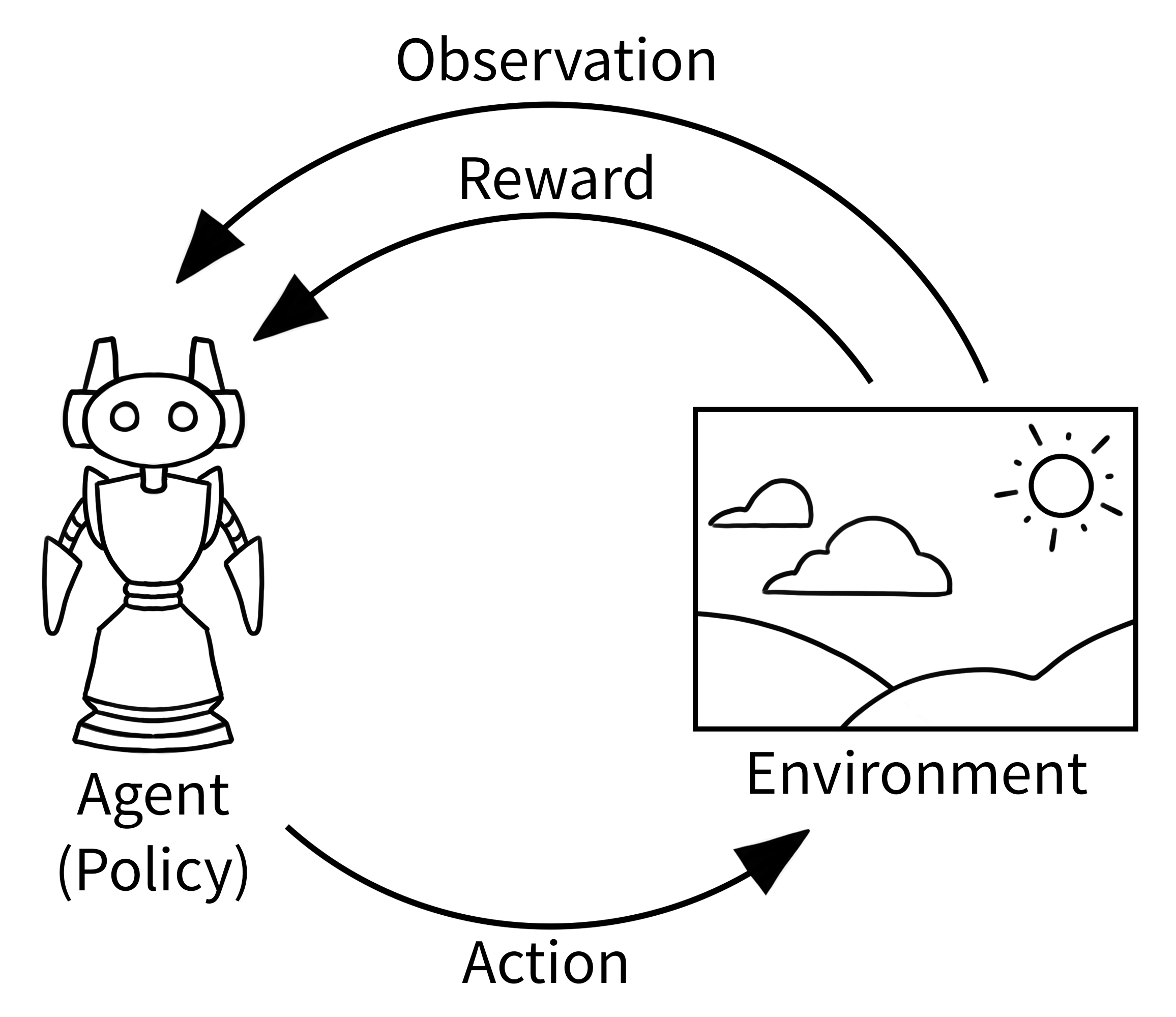
参考上面经典的 “agent-environment loop”,Agent 会收到一个环境的 observation,然后选择一个 action,environment 用它来决定 reward 和下一个 observation。
!pip install swig "gymnasium[box2d]" |
动作和状态空间
任何 environment 都指定了有效的 actions 和 observations,存在 attributes action_space 和 observation_space 里,有助于理解环境期望的输入输出。
Env.action_space 和 Env.observation_space 都属于 Space 类的 instances,主要有两个函数 Space.contains()和 Space.sample()。
Gym 支持很多种数据结构的 spaces:
- Box
- Discrete
- MultiBinary
- MultiDiscrete
- Text
- Dict
- Tuple
- Graph
- Sequence
修改环境
Wrappers 可以修改 environment 而不改变其代码,大多数用 gymnasium.make() 产生的环境都是默认被 TimeLimit (定义一个 truncated timestep)、OrderEnforcing (reset 之前 step 或 render 会报错)、PassiveEnvChecker (检查 reset 是否返回符合规范的初始状态 obs 和信息 info,检查 step 是否返回格式正确的 (obs, reward, done(terminated, truncated), info),检查 render (可选) 是否是合理的可视化)。
其中 PassiveEnvChecker 这层 wrapper 可以在 make 时通过 , disable_env_checker=True 去掉。
除此之外比如 FlattenObservation,
import gymnasium as gym |
unwrapped 可以得到最里面的 base environment。
AtariPreprocessing 也是个 warpper,会完成 Noop Reset (返回执行过随机次 no-op 的 initial state, default max 30 no-ops), Frame Skipping (4 by default), Resize to a square image (210x180 to 84x84 by default), Grayscale observation (默认转灰度图), Grayscale new axis (保留 channel 维度为 1,默认不保留) 等。
自定义环境
- 为
class CustomEnv(gym.Env)实现__init__(包括定义 agent / target location 和 actions) - 构建 observations
- 实现
reset,step - 包装 wrappers
- register / make
ALE
rom_file = "Breakout.bin" # WARNING: Possibly unsupported ROM: mismatched MD5. |
可以这样每次执行一个动作都用 ALE Python interface 保存 screenshots。
用 Gym
用原始 API 比较方便,不用学两套 function,
import gymnasium as gym |
这个 env 其实就是对上面 ALEInterface() 的 wrapper 封装,用下面的方法可以直接操作 base env ALEInterface:
ale_interface = env.unwrapped.ale |
# /Users/v2beach/.pyenv/versions/miniforge3-4.10/lib/python3.9/site-packages/ale_py/ 除了 roms/breakout.bin 就是 env.py |
可以在训练的时候用 rgb array,推理 render 的时候用 human。
Frame Skipping and Preprocessing
这篇文章写得相当好。
Training an Agent
https://gymnasium.farama.org/introduction/train_agent/
Stable Baseline 3
pip install "stable-baselines3[extra]"
直接看代码,反正 Gym ALE Stable-baseline 的 doc 也是直接贴代码。
pre-trained zoo 里 breakout 模型都训了 10M 个 timesteps,作者是这个,打砖块代码分别存在 1, 2, 3 里面。
import gymnasium as gym |