
数据库,简而言之可视为电子化的文件柜——存储电子文件的处所,用户可以对文件中的数据运行新增、截取、更新、删除等操作。
所谓“数据库”系以一定方式储存在一起、能予多个用户共享、具有尽可能小的冗余度、与应用程序彼此独立的数据集合。一个数据库由多个表空间(Tablespace)构成。
一、绪论
基本概念
数据/数据库/数据库管理系统/数据库系统
数据(Data):描述事物的符号记录
数据库(DB):长期存储在计算机内、可共享的、有组织的大量数据的集合
数据库管理系统(DBMS):数据管理软件
数据库系统(DBS):数据库、数据库管理系统、应用程序、数据库管理员构成的存储、管理、处理和维护数据的系统
数据模型
现有的DMS均是基于某种数据模型的,它是对现实世界数据特征的抽象。数据模型分为两种,一是概念模型,主要用于数据库设计;二是逻辑模型和物理模型,逻辑模型用于DMBS的实现, 物理模型是数据在最顶层的表示方式和存取方法。数据模型由数据结构、数据操作、完整性约束条件三部分构成。
概念模型
概念模型是从现实世界到信息世界的认知抽象,仍有较强的语义表达能力,有这样一些基本概念:
实体:客观存在并可相互区分的事物称为实体,比如一个学生、一门课
属性:实体所具有的某一特性,比如学号、院系
码:可以唯一标识实体的属性或属性组合称为码,比如学号是学生实体的码、学号和课程号是学生某门课成绩的码
实体型:属性组合相同的同类实体,比如学生(学号,姓名,性别,出生年月,院系,入学时间)
实体集:同一类型实体的集合,比如全体学生
联系:指的是不同实体集之间的联系,有一对一、一对多、多对多等多种类型
概念模型可以用E-R(Entity-Relationship approach)方法表示。
逻辑模型
大致分为非关系模型和关系模型,在两者基础上建立的数据库即为非关系型数据库和关系型数据库,整门课讨论的主要是老技术,关系模型。
关系模型有这样一些基本概念:
关系:一个关系即通常说的一张表
元组:表中的一行即一个元组
属性:表中的一列即一个属性
码:表中的某个可以唯一确定一个元组的属性或属性组
域:属性的取值范围,比如(男,女)
分量:元组中的一个属性值
关系模式:对关系的描述,比如学生(学号,姓名,性别,出生年月,院系,入学时间)
物理模型
http://coding-geek.com/how-databases-work/ 一片非常棒的讲解,
https://blog.csdn.net/zhangcanyan/article/details/51439012 此为译文。
数据库系统的结构
数据库系统模式的概念
数据模型中有型和值(type and value)的概念,模式即数据库中全体数据的逻辑结构和特征的描述,即模式就是型,不涉及值,模式的一个值称为一个实例。
模式在体系结构上都具有三层模式和两级映像。
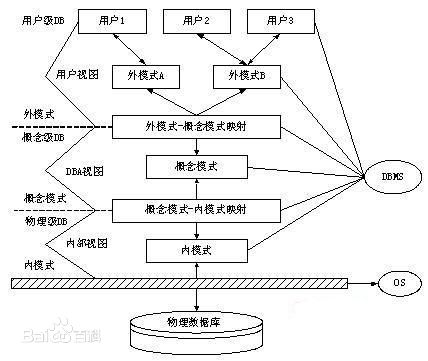
数据库系统的三层模式结构
DBMS从三个层次来管理数据:外部层次、概念层次、内部层次。所谓模式,就是对数据的结构性描述,所以对应不同层次的数据存在不同层次的模式,分别为模式(概念模式/逻辑模式)、外模式(用户模式/子模式)、内模式(存储模式/物理模式)。
外部层次的数据是用户看到的数据,即用户层;概念层次的数据是DBMS全局管理的数据和数据间约束,即逻辑层;内部层次是存储在介质上的数据,涉及存储路径、存储方式和索引方式,即物理层。
三种层次的模式都是对数据的描述,层次和形式不同。
模式
存放数据的时候同样的信息只能分别用同一个表来存,而不能两张结构不同的表却存放同样的学生信息,这些DBMS管理的数据和数据间约束就是模式,只能存在一个。
外模式
为了划分操作权限等原因,从这些关系中提取出视图也就是虚表,给不同角色和用户提供服务,这就是外模式,所以可以存在多个。
内模式
是数据物理结构和存储方式的描述,是数据在数据库内部的组织方式。在介质上存放数据的时候,只能选择某一个特定的存储路径、存储方式、索引方式等,也就是DBMS的底层实现,是个在物理层面上的概念,也即内模式,只能存在一个。
数据库的二级映像功能
外模式/模式映像
对应每一个外模式,数据库都有一个外模式/模式映像,也就是我们构建的视图,在数据库的模式改变(比如增加一列新的属性),可以改变视图的构建方式,从而使外模式保持不变,数据库向外部程序提供的接口是基于外模式视图的,素以程序就不用改变,也就保证了数据(和程序)的逻辑独立性。
模式/内模式映像
数据库中只有一个模式/内模式映像,比如说明某个关系在数据库内部如何存储,当数据库的存储结构变了,只要改变模式/内模式映像,就可以使模式保持不变,进而保证外部应用程序不用改变,也就 保证了数据(和程序)的物理独立性。
二、关系数据库
温故而知新,关系模型是数据模型的一种,属于逻辑模型,数据模型有三个要素,分别是数据结构、数据操作和完整性约束,这里就从三个方面分别定义和分析,并给出一个相对于SQL更理论化的关系代数以描述对关系模型的操作,总共四部分。
关系数据结构的形式化定义
基于关系模型的关系型数据库刚才已经给出了一些非形式化的定义。关系模型只有单一的数据结构—关系,也就是一张扁平的二维表。关系型数据库建立在关系模型的基础上,而关系模型建立在集合代数的基础上,这里从集合论的角度给出关系数据结构中概念的形式化定义。
域(Domain):属性的取值范围,或者说是一组具有相同的数据类型的值的集合。比如100以内的素数、所有实数,这没啥好说。
笛卡尔积(Cartesian Product):简单来说可以想象全连接的神经网络,n个域交叉相乘得到的n维元组(n-tuple)的集合就是结果。比如D1=导师集合={长者},D2=专业集合={电力机械,膜法},D3=学生集合={V2beach},D1xD2xD3={(长者,电力机械,V2beach),(长者,膜法,V2beach)},即一张二维表。
关系(Relation):关系是笛卡尔积的子集,维度n叫做关系的目/度,R(D1,D2,···,Dn)叫n元关系,或者n目关系,必须包含n个属性。一般来说,笛卡尔积没有实际语义,只有它的真子集才有可能包含语义,比如上面的例子,我没有和长者学电力机械,但我学到了很多膜法,前一个三元组这样的笛卡尔积元素是没有意义的。
候选码(Candidate Key):某一属性或属性组的值可以唯一地标识一个元组,但其子集不能,这种属性或属性组叫候选码。
主码(Primary Key):一个关系有一个或多个候选码,选定其中一个为主码。
主属性(Prime Attribute):候选码的诸属性都叫做主属性,不包含在任何候选码里的属性称为非主属性或非码属性。
全码(All-key):关系模式的所有属性都是候选码,就叫做全码。
关系可以有三种类型:基本关系、查询表、视图表。基本表是实际存在的表,是存储数据的逻辑表示;查询表是查询结果对应的表;视图表是由基本表或其他视图表导出的表,是虚表,不对应实际存储的数据。
范式(Normal Form)后面再说,关系模型最基本的一条是关系的每一个分量必须是一个不可分的数据项。
顺便形式化定义一下关系模式,关系数据库中,关系模式是型,关系是值。关系模式形式化地表示为R(U,D,DOM,F),R是关系名,U是关系的属性名集合,D是U中属性的来源域,DOM是属性向域的映像集合,F是属性间数据的依赖关系。F依赖关系也是后面再说,比如研究生学号决定导师和专业就是一种依赖,DOM映像可以理解为,导师和研究生都出自人这个域,但有的人只是老师,有的人只是学生,要描述得更详细才能确定属性名和具体的域集,这个过程就是属性和域的映射。
关系操作
关系模型中常用的关系操作包括查询(query)操作和插入删除修改,两大部分。关系的查询表达能力极强,是关系操作的最主要部分,查询操作可以拆分为选择、投影、连接、除、并、差、交、笛卡尔积等操作,加粗为基本操作,关系操作都是集合操作,对象和结果均为集合,也即关系。
理论中的关系操作常用关系代数和关系演算,分别为代数方式和逻辑方式来表示,结构化查询语言SQL介于二者之间。这里不涉及关系演算ALPHA,那是一种离散数学中谓词逻辑式的描述方式,在此之学习了关系代数和SQL,关系操作都将由它们进行描述。
关系模型的完整性约束
包括实体完整性、参照完整性、用户定义完整性。实体完整性、参照完整性是必须满足的两个不变性,用户定义完整性是应用领域需要遵循的,体现具体领域的语义约束。
实体完整性
实体完整性规则:如果一个属性或属性组A是基本关系R的主属性也就是所谓候选码,则A不能取空值。
By the way,要区分主码和主属性,主属性包括所有候选码里的属性,主码是候选码的子集或者说主码包含的属性是主属性的子集,另外,候选码是没有多余属性的码,比如学生(学号,姓名,性别,出生年月,院系,入学时间),学号是候选码,但学号和姓名就不是,因为学号和姓名的子集学号可以唯一地表示一个元组,但学号和姓名可以称为码。
参照完整性
现实世界的实体往往存在联系,关系模型中,实体和实体间的联系表示方式就是关系,那么自然而然也存在关系和关系之间的联系,或者说引用。
外码(Foreign Key)和参照(Reference):设F是基本关系R的一个或一组属性,但不是关系R的码,K是基本关系S的主码,如果F与K相对应,则说F是R的外码,R是参照关系,S是被参照关系。就是说有两个关系R and S,R里有一个属性或属性组和S中的主码(是主码噢)值取自同一个或同一组域,就说这个S中的主码是R的外码,可以将R和S联系起来,R参照S,但R和S也未必不是同一个关系。
参照完整性规则:若属性或属性组F是基本关系R的外码,与基本关系S中的主码K相对应,则对于R中每个元组在属性或属性组F上的值只能取空值或者在S上存在的主码K值。
用户定义完整性
NOT NULL, UNIQUE等限制,更详细的后面会说。
关系代数
这里从https://keelii.com/2017/02/19/basic-operations-of-relation-algebra/搬运一些定义。
关系代数需要用到我们常见的集合运算符、比较运算符、逻辑运算符,另外还有
专门的关系运算符,
| 运算符 | 含义 | 英文 |
|---|---|---|
| σ | 选择 | Selection |
| π | 投影 | Projection |
| ⋈ | 链接 | Join |
| ÷ | 除 | Division |
别的就不多说了,专门理解这四种运算。
概念理解
专门的关系运算
象集
象集,$Z_x=\{t[Z]\mid t\in R, t[X]=x \}$,关系R(X,Z),假设现在取X属性或属性组中某个值x在R中的象集,那么就是取关系R中X属性=x的元组,除X外的其他属性即Z诸属性的值。
比如关系R为:X值为a,Z值为bc。
a1 b1 c2
a2 b3 c7
a3 b4 c6
a1 b2 c3
a4 b6 c6
a2 b2 c3
a1 b2 c1
那么,a1在R中的象集为{(b1,c2),(b2,c3),(b2,c1)}。
笛卡尔积
两个分别为n目k1个元组和m目k2个元组的关系$R\in \mathbb R^{k_1\times n}$和$S\in \mathbb S^{k_2\times m}$的笛卡尔积是一个(n+m)列元组的集合,$R×S=\{(t_r,t_s)\mid t_r\in R\land t_s\in S\}$。
选择
选择又叫做限制,$σ_F(R)=\{t\mid t\in R\land F(t)=True\}$,表示在关系R中满足F条件的所有元组,F为XθY,θ是比较运算符,X和Y是属性名或常量。
投影
投影,$π_A(R)=\{t[A]\mid t\in R\}$,是从关系R中选择出若干属性列组成一个新的关系,是从列角度进行的运算,A为R中的一个Attribute属性列。
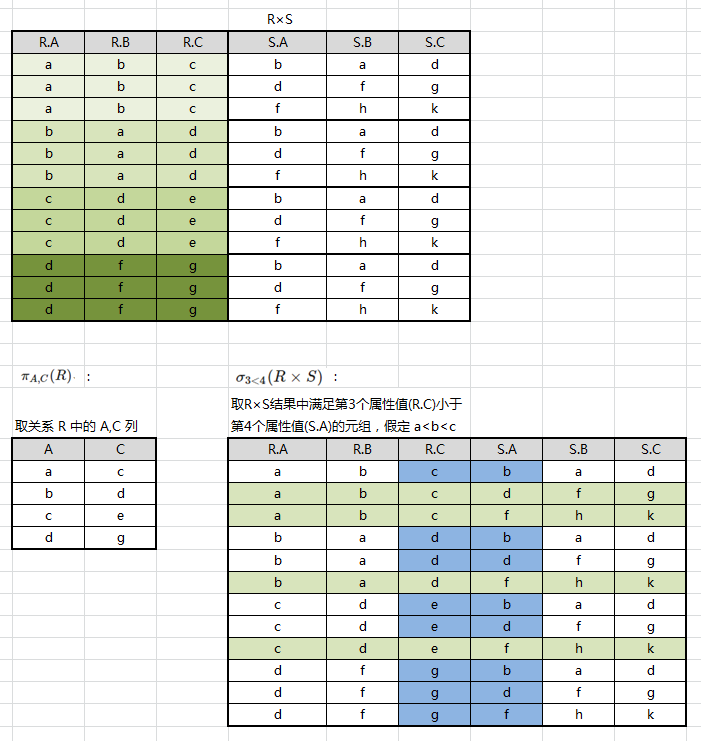
连接
连接也称为$θ$连接,$R\Join_{XθY}S = σ_{XθY}(R×S)$LaTeX里面这\Join就是不允许添加\limits,连接可以从两个关系的笛卡尔积里选出满足XθY条件的元组。
连接有很多种,最常用的是等值连接和自然连接,另外还有外连接,左外连接等。
等值连接
即XθY为X=Y,从R和S中选出X和Y属性相等的元组,然后两张表连在一起,只去除不满足X=Y的元组,属性列不做处理,即处理后的R和S直接连在一起构成一个关系,和自然连接放在一起理解。
自然连接
自然连接是特殊的等值连接,不需要指定X=Y的X和Y,会自然地取相同的属性列,做等值连接。连接之后去除重复的属性列,得到连接结果。
例如:设有关系 R、S 如图所示,求 R⋈SR⋈S
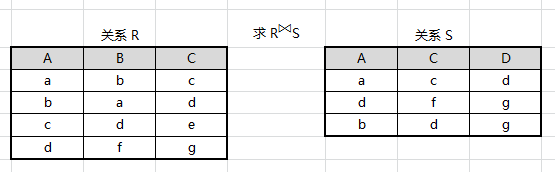
先求出笛卡尔积 R×SR×S,找出比较分量(有相同属性组),即: R.A/S.A 与 R.C/S.C
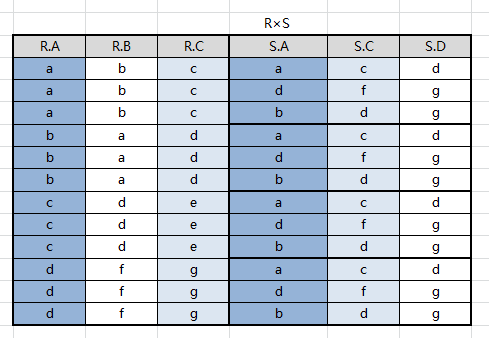
取等值链接 R.A=S.AR.A=S.A 且 R.C=S.CR.C=S.C
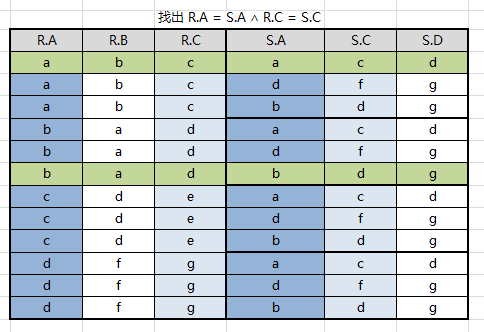
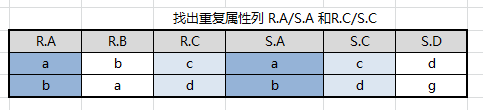
结果集中去掉重复属性列,注意无论去掉 R.A 或者 S.A 效果都一样,因为他们的值相等,结果集中只会有属性 A、B、C、D
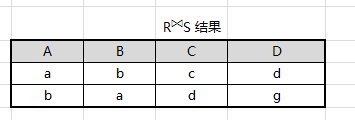
最终得出结果
外连接
由于没有满足等值条件删除掉的元组叫悬浮元组,无法匹配的元组缺省值为NULL,不去除任何元组的连接就是外连接,其中左外连接,就是保留所有左边关系的悬浮元组,不满足条件的元组,右外连接同理。
除
除,$R÷S=\{t_r[X]\mid t_r\in R\land π_Y(S)\subseteq Y_x\}$ ,得到结果关系T,T包含所有在R但不在S中的属性和值,T的元组和S的元组的所有组合都在R中。
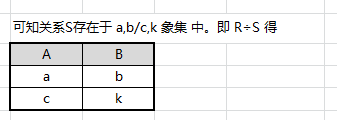
用象集定义除法,上面那个形式化的式子其实是这样的含义:给定关系R(X,Y)和S(Y,Z),其中X、Y、Z为属性组。R中的Y与S中的Y可以属性名不同但是域集必须相同。R对S的除运算得到一个新的关系P(X),P是R中满足以下表达的元组在X属性列上的投影:元组在X上分量值x的象集$Y_x$包含S在Y上投影的集合,也就是$R÷S=\{t_r[X]\mid t_r\in R\land π_Y(S)\subseteq Y_x\}$,其中$Y_x$是x在R中的象集,$x=t_r[X]$。
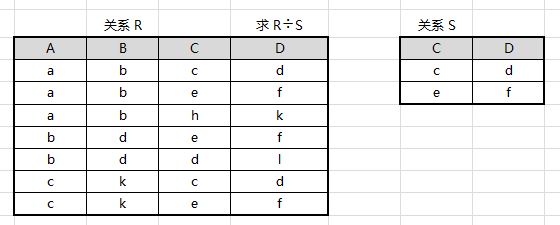
从R中找出S的属性CD所有的象集的交叉,也就是找到能同时包含所有CD(cd ef)值的元组,然后投影到AB上,关系S如果是CDE也只取CD,结果在R中所对应的元组集要同时包含CD的所有值。
练习
分为关系代数和MySQL两个版本,放在下一章内容里,因为所有题都用关系代数和SQL一起实现,而且涉及关系代数的题目一般都有点难度。
三、关系数据库的标准语言SQL
本章主要就是理解并实现在MySQL上的所有数据库操作。
模糊概念
SQL
SQL:结构化查询语言,关系数据库的标准语言,介于代数和逻辑表达之间,虽然叫做查询语言,但此query并非彼select,意思是可以通过这个语言完成和数据库的数据交流。
索引
索引:首先,索引是内模式的范畴,也就是底层实现的内容,不必自行选择。然后,没有索引的话就意味着查询时要一个一个元组对比来查找项,索引是为了加快查询而产生的,索引是在基本表之外的独立文件,有B-Tree, Hash, 位图等多种索引(索引是一种数据结构),当通过索引效率极高地查找到符合要求的项之后,索引提供一个指针指向相应关系的内存位置,以返回结果。关于索引一篇翻译的好文章https://blog.csdn.net/weiliangliang111/article/details/51333169。
数据字典
数据字典:待会数据库完整性会用到的概念,数据字典是关系DBMS内的一组系统表,记录数据库中所有的定义信息(关系模式定义、视图定义、索引定义、完整性约束定义、各类用户的权限、统计信息等),关系DBMS执行SQL的DDL数据定义语句时实际上就是在更新数据字典表的信息。查询优化和查询处理中数据字典中的信息是重要依据。
字符匹配
字符匹配:LIKE or NOT LIKE,%代表0~∞长度的任意字符,_通配符代表单个任意字符。规则是,比如要查询以 \’V2beach\’ 开头,倒数第三个字符为 \’柳\’ 的用户情况,select * from xx where user LIKE ‘V2beach#_%柳__‘ ESCAPE \’#\’,表示#在这里当作转义字符,#_代表_,下划线不再是通配符,可以匹配到V2beach_xxxxx柳gg这样的字符串,熟悉正则就一眼明白了。
数据库内的排序
数据库内的排序:ORDER BY xx ASC,结果按xx升序;ORDER BY xx DESC,结果按xx降序。select的子句中不能用order by,只能对最终查询结果排序。
聚集函数
聚集函数:有两种情况,分别是单独使用和同GROUP BY一同使用。COUNT([distinct|all] <列>), SUM([distinct|all] <列>), AVG([distinct|all] <列>), MAX([distinct|all] <列>), MIN([distinct|all] <列>)常用的就这几种。用法是:单独用比如select count(*) from xx;返回总行数,再比如select avg(grade) from sc;返回平均成绩;同group by一起使用比如select Sno from SC group by Sno having count(Cno) >= 2返回选了两门课以上的学生学号,再比如select from dept group by major having avg(grade) >= 80将年级所有学生按专业划分,然后返回专业学生成绩高于80分的班级情况。也就是说不分组时,只能用于select子句,聚集函数作用与所有行;分组后,只能用于group by后的having子句,聚集函数作用于组,即每组只有一个函数值。聚集函数不能嵌套如count(avg(xx)),但是参数可以是函数表达式,并且会自动*忽略NULL不参与计算。
连接操作
连接操作:where复合子句进行连接之后,限定条件多可以提高连接效率,另外表可以自身连接,只要内容可比即可,外连接比如左外连接用left outer join,多表连接用and多次连接即可。
另外可以参考https://www.oschina.net/translate/mysql-joins-on-vs-using-vs-theta-style学习理解一下连接中的on/using/theta的区别。
SELECT * FROM film JOIN film_actor ON (film.film_id = film_actor.film_id) |
嵌套查询
嵌套查询:IN,EXISTS…传统方式select from where构成一个查询块,将一个查询块嵌套在另一个where或having语句中就叫嵌套nested query,
SELECT * |
上层叫外层或父查询,下层叫内层或子查询,这种层层嵌套就是SQL Structured的含义。
不相关子查询
select dept |
这种子查询和父查询无关的叫做不相关子查询。
相关子查询
select dept |
这种子查询的查询条件依赖于父查询的叫做相关子查询,整个查询语句就叫做相关嵌套查询。
IN谓词子查询
in子查询返回一个集合,父查询的元组在集合中时为真,反之not in则不在集合中为真。
比较运算子查询
当确切知道子查询返回一个值,就可以用=等比较符代替其他谓词。
ANY(SOME) ALL谓词子查询
当子查询返回多值的时候,比较运算符就要加ANY(SOME) ALL谓词,或者说ANY(SOME) ALL谓词前必须要加比较运算符,
| = | <>或!= | < | <= | > | >= | |
|---|---|---|---|---|---|---|
| ANY | IN | - | <MAX | <=MAX | >MIN | >=MIN |
| ALL | — | NOT IN | <MIN | <=MIN | >MAX | >=MAX |
比如,
select sname, sage |
上式的语义是找出非计算机科学系中比计算机科学任何一个学生年龄都小的男生,可以用聚集函数代替。
select sname, sage |
EXISTS谓词子查询
EXISTS和IN有所不同,EXISTS是在子查询中查值,若返回集合非空则where为true,不返回任何数据,只是将值代入条件进行判断,所以子查询一般写作select *,给出属性名并无意义。
比如查询选修了学生20172332333所选全部课程的学生学号,EXISTS代表 ∃ ,SQL中没有全称量词 ∀ ,所以可以通过谓词逻辑将此题转化,这里就不那么麻烦了。
select distinct sno |
EXISTS和IN查询比较
https://www.jianshu.com/p/f212527d76ff说的不错,但评论指出IN也是要走索引的,是一个错误。
嵌套查询和连接查询的比较
https://blog.csdn.net/leimengyuanlian/article/details/7854902这有一篇未知正误的比较,没时间详细研究了,以后填坑。
集合查询
就是将结果用集合运算UNION∪、INTERSECT∩、EXCEPT-操作再次运算得到结果。
视图
视图:视图是从基本表中导出的虚表,数据库存放视图的定义但是不独立地存数据,基本表的数据改变视图也随之改变,视图就像一个窗口,从数据库中投射出感兴趣的数据和变化。
有student表如下,比如我现在是数据库管理员,要分给计算机科学系主任看计科系所有学生信息的权限,那么就需要在这张表基础上创建视图。
| Sno | Sname | Ssex | Sage | Sdept |
|---|---|---|---|---|
| 201215121 | 李勇 | 男 | 20 | CS |
| 201215122 | 刘晨 | 女 | 19 | CS |
| 201215123 | 王敏 | 女 | 18 | MA |
| 201215125 | 张立 | 男 | 19 | IS |
create view CS_student_1 |
这时使用select * from CS_student_1;便可达到目的,
| Sno | Sname | Ssex | Sage |
|---|---|---|---|
| 201215121 | 李勇 | 男 | 20 |
| 201215122 | 刘晨 | 女 | 19 |
但是假设系主任有其他操作权限,做其他操作的时候,加了with check option就可以保证再修改时也满足子查询的where条件表达式。
DBMS只是保存了这个视图的定义在数据字典内,这种从单个基本表导出来的,只是可能删除了某些行列的,叫做行列子集视图。
视图可以像(no, name, sex, age)这样重命名,也可以在select中包含表达式,同样可以用聚集函数和group by来创造分组视图。
删除视图用DROP VIEW CASCADE。
查询视图
要明确视图和派生表是有区别的,派生表查询在from内构造,查询完就被删除了,视图的定义永久存在于数据字典中。
关系数据库中对视图进行查询时,首先进行有效性进行检查,即能否找到对应的视图和关系,然后进行试图消解。
视图消解指的是DBMS从数据字典中取出视图的定义,把定义中的子查询和用户的查询结合转化为对基本表的一个独立的查询语句,再执行这个查询,相当于把视图忽略了只在乎子查询语句。
比如select from CS_student_1 where Sage<20; 就消解为 select from student where Sdept=’CS’ and Sage<20;。
如果不是行列子集视图,假如视图是create view v(Savg) as select avg(grade) from sc group by sno; 执行select * from v where Savg>90; 会消解为select avg(grade) from sc where avg(grade)>90 group by sno,应当有having,此处会出现错误。
更新视图
更新视图同样需要将对视图的操作自动转化为对基本表的操作。有些视图不可更新,比如avg运算后的视图,改变平均分无法独立地改变基本表,所以不能更新。
视图的作用
主要可以1.简化用户操作;2.从多个角度灵活看同一数据;3.对重构数据库(增加新属性或者添加新关系)提供了一定程度逻辑独立性;4.对机密数据提供安全保护;5.更清晰表达查询(先构建视图再在视图中查询)。https://blog.csdn.net/fm0517/article/details/5625949读一遍,详情见教材。
关系代数和SQL练习
分为关系代数和MySQL两个版本。题目来源:https://blog.csdn.net/Bruce_why/article/details/46389603。
另外《数据库系统概论》第五版,p44—「关系操作的特点是集合操作方式,即操作的对象和结果都是集合。」,集合的元素不能重复,所以这里认为对象和结果的集合都缺省DISTINCT。
题A:
设有如下所示的关系S(S#,SNAME,AGE,SEX)、C(C#,CNAME,TEACHER)和SC(S#,C#,GRADE),用关系代数表达式表示下列查询语句:
(1) 检索“程军”老师所授课程的课程号(C#)和课程名(CNAME)。
(2) 检索年龄大于21的男学生学号(S#)和姓名(SNAME)。
(3) 检索至少选修“程军”老师所授全部课程的学生姓名(SNAME)。
(4) 检索”李强”同学不学课程的课程号(C#)。
(5) 检索至少选修两门课程的学生学号(S#)。
(6) 检索全部学生都选修的课程的课程号(C#)和课程名(CNAME)。
(7) 检索选修课程包含“程军”老师所授课程之一的学生学号(S#)。
(8) 检索选修课程号为k1和k5的学生学号(S#)。
(9) 检索选修全部课程的学生姓名(SNAME)。
(10) 检索选修课程包含学号为2的学生所修课程的学生学号(S#)。
(11) 检索选修课程名为“C语言”的学生学号(S#)和姓名(SNAME)。
The problem solution given by V2beach:

The problem solution given by the problem provider:
(1) 
(2) 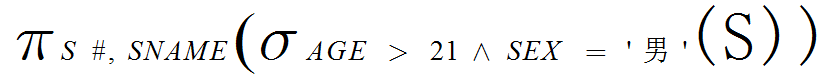
(3) 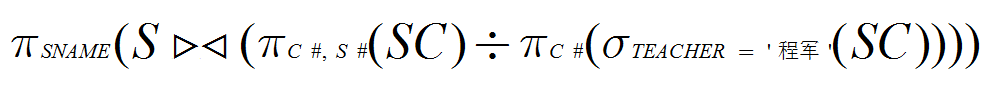
(4) 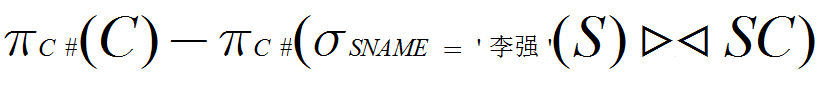
(5)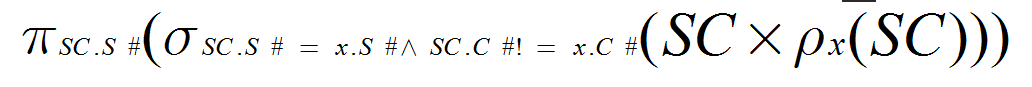
(6) 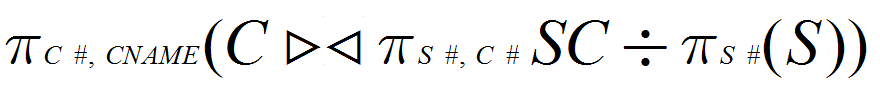
(7) 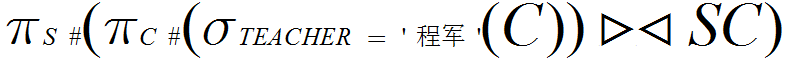
(8) 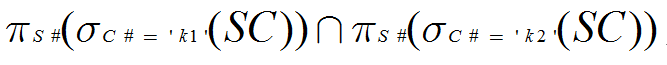
(9) 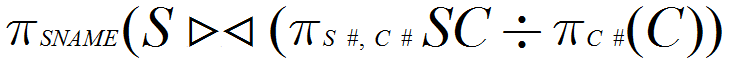
(10) 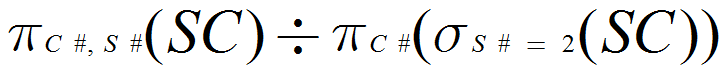
(11) 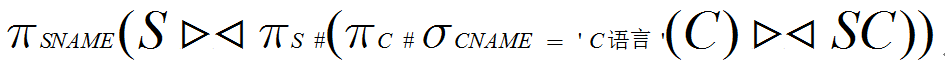
题B:
已知一个关系数据库的模式如下:
S (SNO,SNAME,SCITY)
P (PNO,PNAME,COLOR,WEIGHT)
J (JNO,JNAME,JCITY)
SPJ (SNO,PNO,JNO,QTY)
供应商S由供应商代码SNO、供应商姓名SNAME、供应商所在城市SCITY组成;零件P由零件代码PNO、零件名PNAME、颜色COLOR、重量WEIGHT组成;工程项目J由工程项目代码JNO、工程项目名JNAME、和所在城市JCITY组成;供应情况SPJ由供应商代码SNO、零件代码PNO、工程项目代码JNO、供应数量QTY组成。
用关系代数表达式表示下面的查询要求:
(1)找出向北京的供应商购买重量大于30的零件的工程名。
(2)求供应工程J1零件的供应商代码
(3)求供应工程J1零件P1的供应商代码
(4)求供应工程J1零件为红色的供应商代码
(5)求没有使用天津供应商生产的红色零件的工程项目代码
(6)求至少用了供应商S1所供应的全部零件的工程项目代码
The problem solution given by V2beach:
(供应商 suppliers ,工程 jobs ,零件 parts)这么记别混淆…

#1 |
The problem solution given by the problem provider:
(1)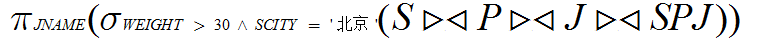
(2)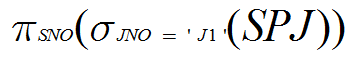
(3)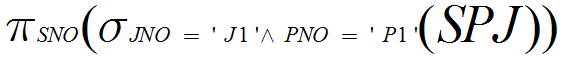
(4)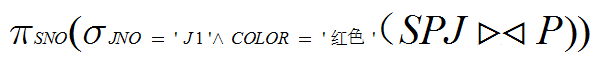
(5)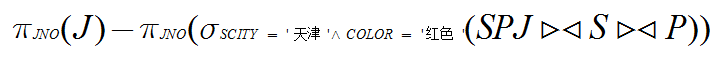
(6)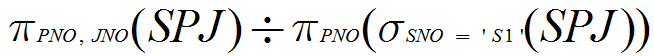
四、数据库安全性
数据库安全是什么
数据库安全的框架是怎样的?在数据库系统中安全措施是一级一级层层设置的。第一层,用户要求访问系统的时候,系统首先根据标识进行身份鉴定,判断用户是否合法;第二层,合法用户访问时,数据库管理系统对用户进行存取控制,这章主要学的也就是DBMS的存取控制这部分内容;第三层,操作系统的安全保护是保护数据库安全的前提,通过分布存储、防火墙等方式防止服务器被攻陷;第四层,数据库内部可以将信息加密存储。
也就是说,假如对方绕过了你的存取控制,不去用合法权限操作而直接攻击服务器操作系统,那么就要在这层上做好安全措施防止数据库系统被攻陷,或者对方找到了操作系统的漏洞,掌控了操作系统,至少要将数据加密以无法让对方获取到真实数据和信息。
这里不谈操作系统,本课程是只涉及了DBS相关的安全性措施,主要是用户身份鉴别、多层存取控制、审计、视图和数据加密等安全技术。
用户身份鉴别
这是信息安全要学的东西,这里研究不着。
存取控制
存取控制机制主要包括定义用户权限和合法权限检查两部分,也就是分配权限和权限检查。两者一同构成了DBMS的存取控制子系统,C2级DBMS支持自主存取控制,B1级支持强制存取控制。
自主存取控制是对不同数据库对象有不同权限,不同用户对同一对象也有不同权限,也可以转移权限,所以很灵活,也就是说对于某些权限可以灵活分配。
强制存取控制强调强制,是由系统分配了不同的密级,分别有固定的权限等级,然后给用户分配访问许可,许可满足要求才可访问一定密级的数据。
用户和角色:用户是当前登陆系统的主体,有注册时分配的用户id和口令,角色是权限的集合,更方便为用户分配权限。定义方法如下,MySQL中用户是用户名@主机名的形式。
create user 'U1'@'localhost' identified by 'U1';create role R1; |
分配权限:GRANT 权限 ON 对象类型 对象名 TO 角色/用户 / GRANT 角色 TO 用户/角色。
收回权限:REVOKE 权限 ON 对象类型 对象名 FROM 角色/用户。
视图机制
可以根据上述的存取控制,为不同用户定义不同视图,在视图上分配权限,更加灵活也更加安全。
审计
审计功能把用户对数据库的所有操作自动记录下来放入审计日记(Audit Log)中,审计员可以通过审计日记监控数据库中的所有行为,重现非法行为。同样,也可以对审计日记分析,对威胁进行防范。
在MySQL中没有标准SQL的AUDIT语句,可以通过安装插件,
set global server_audit_logging=on ,
然后从server_audit.log中读到所有操作的记录,
等方式完成审计功能。
数据加密
数据加密主要包括存储加密和传输加密,存储加密是将数据库中的数据使用加密算法把明文转为密文存储,传输加密会使用基于安全套接层协议(SSL)等数据库管理系统的可信传输方案。
其他安全性保护
推理控制,处理用户可以通过可自己可观察的信息推理隐秘信息的情况。
还有隐蔽信道等。
五、数据库完整性
怎么维护数据库完整性
为了维护数据库的完整性,DBMS需要具备几种功能。首先,要提供定义完整性约束条件的机制,包括关系模型中的实体完整性、参照完整性、用户定义完整性等,通过数据定义语言实现之后作为数据库逻辑模式的一部分存入数据字典,数据字典大体上包含所有数据相关的信息;其次,要提供完整性检查方法,在INSERT、UPDATE、DELETE语句执行完后进行检查,或是在事务提交时检查,检查操作后是否违背了完整性约束条件;最后要有进行违约处理的措施,比如拒绝执行或者级联进行其他操作,以保证数据库的完整性。
下面围绕就这三个方面,学习一些方法,基于MySQL。
定义完整性约束的机制
定义实体完整性
可以列级也可以表级。
create table Student( |
定义参照完整性
参照完整性约束(外码)都是表级的
create table SC( |
也可以用完整性约束命名子句来定义
(MySQL不适用)ALTER TABLE xxx DROP/ADD CONSTRAINT xxx。
create table teacher ( |
触发器
触发器类似于约束,但是比约束更加灵活,可以实施比FOREIGN KEY约束、CHECK约束更复杂的检查和操作;
触发器创建:CREATE TRIGGER <触发器名字> {BEFORE | AFTER} <触发事件> ON <表明> FOR EACH {ROW | STATEMENT} [WHEN <触发条件>] <触发动作体>
激活触发器:同一个表触发器激活时遵循的执行顺序:
1、执行该表上的BEFORE触发器;
2、激活触发器的SQL语句;
3、执行该表上的AFTER触发器。
删除触发器:DROP TRIGGER <触发器名> ON <表名>
只能由具有相应权限的用户删除触发器。
完整性检查机制和违约处理
实体完整性检查机制和违约处理
在插入一条记录或对主码列进行更新操作时进行。
检查是否唯一或各个属性是否为空—通过B+树建立的索引来判断。
如果不唯一或任一属性值为空则拒绝插入或修改。
参照完整性检查机制和违约处理
| 被参照表 | 参照表 | 违约处理 |
|---|---|---|
| 可能破坏参照完整性 | 插入元组 | 拒绝 |
| 可能破坏参照完整性 | 修改外码值 | 拒绝 |
| 删除元组 | 可能破坏参照完整性 | 拒绝/级连删除/设置为空值 |
| 修改主码值 | 可能破坏参照完整性 | 拒绝/级连删除/设置为空值 |
用户定义完整性检查机制和违约处理
当往表中插入元组或修改属性值时,检查约束条件是否满足,不满足则拒绝执行。
触发器
MySQL中触发器定义有所不同:
delimiter | |
删除:drop trigger xx on \
事件:事件是指对数据库的插入、删除、修改等操作。触发器在这些事件发生时将开始工作。
条件:触发器将测试条件是否成立。如果条件成立,就执行相应的动作;否则什么也不做。
动作:如果条件满足,则执行这些动作。
执行insert操作:插入到触发器表中的新行同时被插入到NEW表中。
执行delete操作:从触发器表中删除的行被插入到OLD表中。
执行update操作:先从触发器表中删除旧行,然后再插入新行。其中被删除的旧行被插入到OLD表中,插入的新行同时被插入到NEW表中。
另:数据库的完整性是为了保证数据库中存储的数据是正确的,删除表同时默认删除触发器。
六、 关系数据理论,范式
关系数据理论是什么
前面几章学的都是关系模式的分支知识,从关系操作和关系代数和SQL表示和关系模型的数据结构、关系操作、完整性约束的实现以及数据库安全性的实现几个方面,完整地理解了如何创建、使用、维护一个关系型数据库系统,也就是关系数据库的基础内容,本章从应用层面来学习数据库。
针对一个具体问题,如何构造一个适合于它的数据库模式?也就是如何构造合适的一系列关系来存储并使用数据?具体来说构造几个关系模式,关系模式分别由哪些属性组成?也就是关系数据库的逻辑设计问题,即数据库设计问题。也是一个很基本的问题。
关系模型有严格的数学理论基础,也可以转换为其他的数据模型,所以在关系模型的基础上研究形成了一个数据库逻辑设计的工具—关系数据库的规范化理论。这章内容主要就是规范化的理解。
一堆废话。
基本概念
关系模式的形式化描述
回顾一下,关系模式可以形式化表示为五元组R(U,D,DOM,F),R是关系名,U是属性,D是U中属性的取值,DOM是属性向域的映像,F是U上的一组数据依赖。D属性取值,DOM属性组的选择域集的选择,都涉及到具体的值,这章只需要用到诸属性和数据依赖,D,DOM与模式设计关系不大,所以在数据库设计的这一章关系模式简化为一个三元组,R
什么是一个好的关系模式
一个好的关系模式不会发生插入异常、删除异常、更新异常,数据冗余要尽可能少。
数据依赖
考点
1.数据依赖是一个在关系内属性与属性之间的一种约束关系;2.这种约束关系是通过属性间值的相等与否体现出来的数据间相关联系;3.是现实世界属性间相互联系的抽象;4.是数据的内在性质;5.是语义的体现。
数据依赖有很多种,最重要的也是这章要学的是函数依赖和多值依赖。
规范化
函数依赖
设R(U)是属性集U上的关系模式,X、Y是U的子集。若对于R(U)的任意一个可能的关系r,r中不可能存在两个元组在X上的属性值相等,而在Y上的属性值不等,则称X函数确定Y或者Y函数依赖于X,记作X$\rightarrow$Y。
平凡函数依赖
X$\rightarrow$Y,Y$\subseteq$X平凡,比如码里包含Y。
非平凡函数依赖
X$\rightarrow$Y,Y$\subseteq$X平凡,比如码里包含Y。
完全函数依赖
传递函数
码
老生常谈,又是码。
码毫无疑问是关系模式中的一个重要概念,这里再从数据依赖的角度理解码。
范式
参考这位老师的答案进行理解https://www.zhihu.com/question/24696366/answer/29189700。
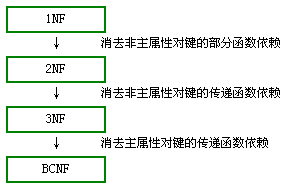
1NF
2NF
3NF
BCNF
多值依赖
4NF
https://www.jianshu.com/p/abf48dfec989
https://www.zhihu.com/question/24696366/answer/29189700
照着这俩答案理解了一下, 先去考试了。
总结
不写了不写了,绝对不写博客复习了。
这样复习效率低,也帮不上别人忙,还不如自己闷声复习,最多梳理个框架。
大家自求多福吧♪(\^∇\^*)
—2019-12-27