
人工智能(英语:Artificial Intelligence,缩写为AI)亦称智械、机器智能,指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术。该词也指出研究这样的智能系统是否能够实现,以及如何实现。同时,通过医学、神经科学、机器人学及统计学等的进步,常态预测则认为人类的无数职业也逐渐被其取代。
本文是对人工智能基础的期末复习知识总结。
在下面两篇文章中有本文部分算法的C++实现,有兴趣的话可以选择性阅读。
算法学习—排序、图、回溯(最小冲突、遗传)、动态规划基础算法复习
以罗马尼亚问题为例,学习人工智能DFS/A*搜索算法
一、绪论
什么是人工智能?
从模拟人的角度来说,可以通过认知建模的过程让机器学会像人一样思考,可以以通过图灵测试为目标让机器具有和人一样的行为;而让机器模拟人并不是我们的目的,这里学习人工智能的是让机器具备理性(rationality),指的是通过思维法则的途径让机器学汇理性的思考,通过理性Agent的构造让机器具有理性的行为。这是四个维度不同层面的解释。
发展历史就不谈了,整体上是以十年为一个周期的发展态势,没意思。
什么是图灵测试?
图灵测试由Alan Turing在1950年提出,内容可以简单描述为,由一个人类询问者提出一些书面问题之后,无法判断书面回答是来自计算机还是人类,就说这台计算机通过了图灵测试。图灵测试是一个至今仍合适的测试,人工智能的研究者并没有一直致力于让计算机通过图灵测试,研究智能的基本原理比复制人类智能或让计算机模拟人更加重要。
人工智能的研究范围有哪些?
知识表示(语义网络等)、搜索技术(博弈树搜索等)、非经典逻辑&非经典推理(时序逻辑等&类比推理等)、机器学习(统计学习等)、自然语言理解(语法学等)、知识工程(专家系统等)、定理机器证明(归纳法等)、人工生命(细胞自动机等)、机器人(传感器数据融合等)、AI语言(Lisp/Prolog等)。
二、Agent
什么是Agent?
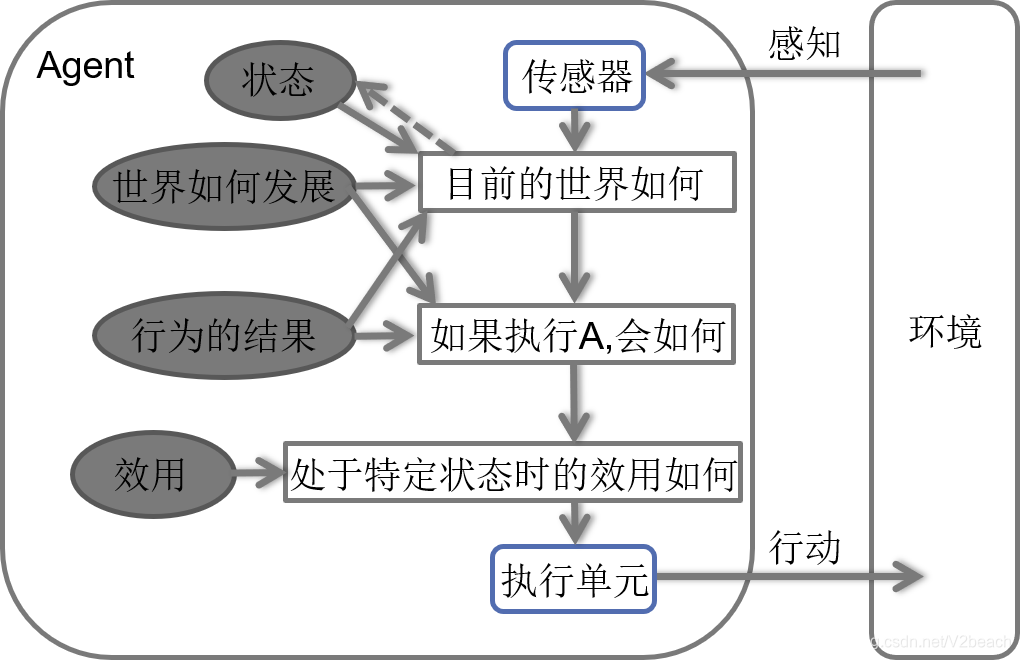
Agent是可以感知环境并且在环境中行动的东西。
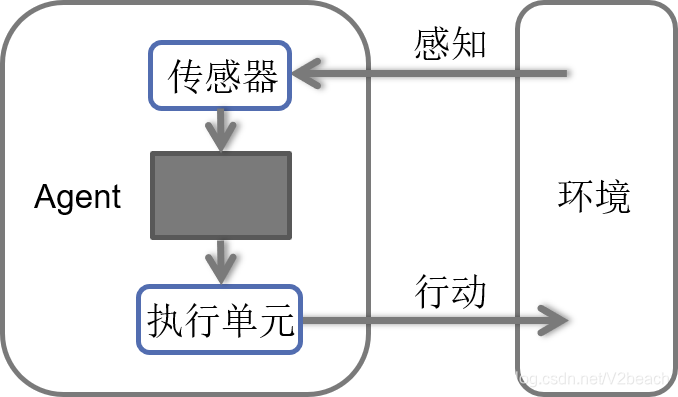
Agent通过传感器感知环境,通过执行器对环境产生影响。Agent收到的所有输入数据的历史序列叫做感知序列,Agent在任何时可的行动选择依赖于到那个时刻为止该Agent的感知序列。Agent=体系结构+程序,体系结构就是图上所表现的,具备传感器和执行器的计算装置,计算装置上运行着Agent程序,程序实现的是从感知序列映射到行为的Agent函数。
Agent函数描述了Agent的行为,可以通过表格描述,Agent函数是抽象的数学描述,Agent程序是具体的实现。
什么是理性Agent?
理性Agent是做事正确的Agent,这是个很模糊的概念,准确来说,理性Agent是对每一个可能的感知序列,根据已知的感知序列提供的证据和Agent具有的先验知识,理性Agent应该选择能使其性能度量最大化的行动。所谓性能度量就是对Agent行为的评价,具体问题具体分析。以吸尘器的例子为例,性能度量是一定时间段内清理的灰尘总量,另外还有其他度量指标,比如保持干净地面加分,能耗高噪声大则减分。
这里有一个讲到的点,理性≠全知/完美,全知/完美是让实际的性能最大化,可以预见行动产生的实际结果并作出相应的动作,而理性只是将期望中的性能最大化。
如何构建理性Agent?
Agent要从环境中通过传感器收集信息,通过程序做出合理的行动指示,才能通过执行器对环境做出符合预期的行为。那么构建理性Agent就有三方面任务,第一是收集准确且足够的环境信息,第二是有合适的体系结构包括传感器和执行器,第三也是最关键的,是要设计出满足AI需求的Agent程序。
在书中24和25章才讲到了传感器和执行器,就不提了,主要学的是设计Agent程序。
首先要尽可能完全地定义任务环境,也就是明确Agent要解决的基本问题,然后是简单了解4种基本的Agent程序。
Ⅰ.任务环境描述—PEAS(Performance 性能 Environment 环境 Actuators 执行器 Sensors 传感器)
比如:
| Agent类型 | 性能度量P | 环境E | 执行器A | 传感器S |
|---|---|---|---|---|
| Taxi driver | 安全、快捷、合法、舒适性、利润最大化 | 道路、其他车辆、行人、乘客 | 方向盘、油门、刹车、车灯、喇叭、显示输出设备 | 摄像头、声呐、车速表、GPS、里程表、加速度计、乘客输入设备 |
Ⅱ.任务环境的性质
完全可观察的
传感器在每个时刻都能获取环境的完整状态,
若传感器能检测所有与行动决策相关的信息,则称为有效完全可观察的。
部分可观察的
噪声、传感器不够精确、传感器丢失了部分数据,则环境是部分可观察的。
单Agent、多Agent
环境中如果有多个对象,那么多个对象的行为是否依赖于其他对象的性能度量。
确定的、随机的
如果环境的下一个状态完全取决于当前状态和Agent执行的动作,则该环境是确定的,
否则,是随机的,也就是说后果是不确定的,可以用概率来量化。
片段式的
Agent的经历被分成一个一个的片段,下一个片段不依赖于以前的片段中采取的行动。
延续式的
当前的决策会影响到所有未来的决策。
静态的
环境在Agent计算的时候不会发生变化,
Agent在决策时不需要观察环境,也不需要顾虑时间流逝。
动态的
环境在Agent计算的时候会变化,
会持续的要求Agent做决策。
半动态的
环境本身不随时间变化,而性能度量随时间变化。
离散的、连续的
指环境的状态、时间的处理方式,以及Agent的感知信息和行动,
如出租车Agent的环境的状态就是连续的,随时间而变化,驾驶行动也是连续的。
已知的、未知的
指Agent的知识状态,
在已知环境中,Agent行动的所有后果是给定的。
在未知环境中,Agent需要学习环境是如何工作的,以便做出更好的决策。
Ⅲ.Agent程序
输入参数:从传感器得到的当前感知信息;返回值:执行器的行动决策。
这里有四种基本的Agent程序。
简单反射Agent
简单反射Agent,最简单的Agent – 基于当前的感知选择行动,不关注感知历史。仅仅根据当前感知的环境信息匹配规则,得出行为决策。
环境必须是完全可观察的。
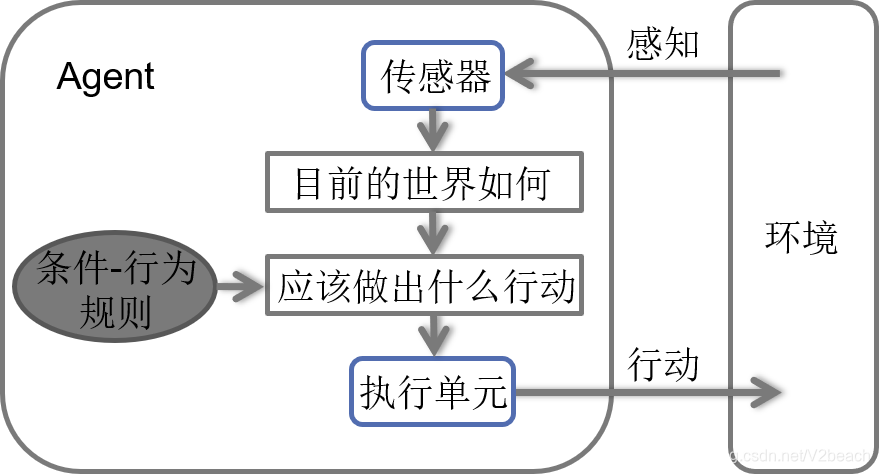
基于模型的反射Agent
基于模型的反射Agent,在简单反射Agent根据当前感知的环境信息决策的基础上,结合当前的信息和过去内部状态得到当前行为决策。内部状态是靠感知历史维持的,会加入世界如何发展,行动会如何影响世界如何产生结果的信息。
可处理部分可观察的环境。
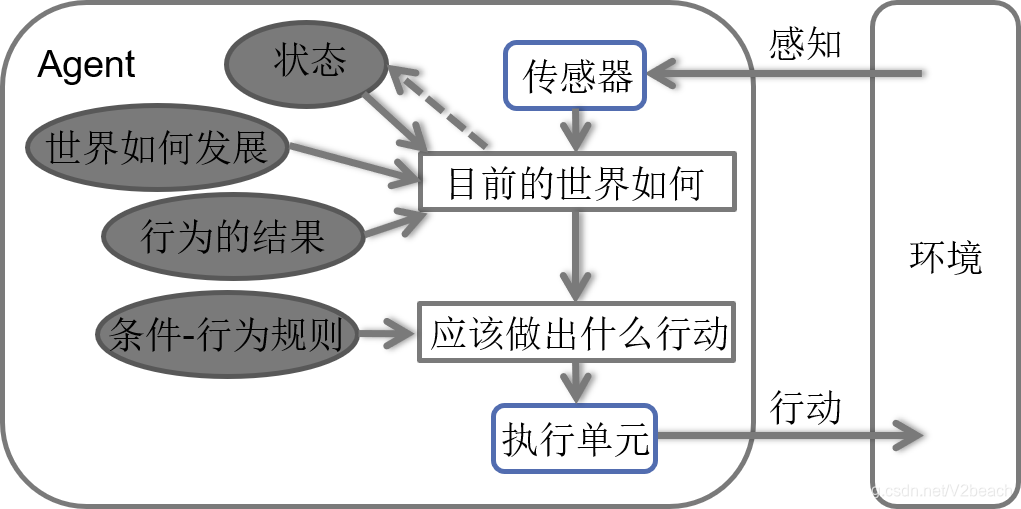
基于目标的Agent
基于目标的Agent,在基于模型的反射Agent根据当前感知的环境信息决策+过去内部状态的基础上,结合模型和增加的目标信息,同时记录世界的状态和目标集合,根据目标灵活改变行动序列来达成目标,方式包括搜索和规划。
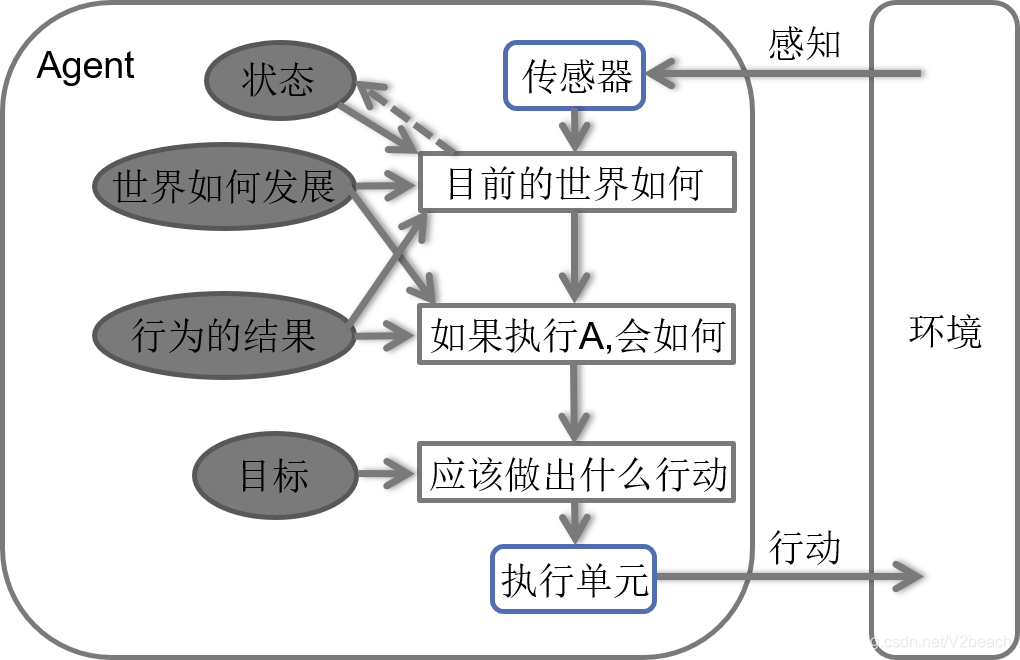
基于效用的Agent
基于效用的Agent,在基于目标的基础上加入对效用的评价,追求对达到目标的最优化途径,通过效用函数决策。
可用在部分可观察和随机的环境中处理不确定性的决策。
三、搜索
上文的基于目标的Agent程序提到了,这类问题的解法会根据目标灵活地找出一个行动序列,而采用的方法是搜索或是规划,规划不学,以后有时间自学,这里搜索是一个大章,我尽量理解清晰,用简洁的语言总结清楚。
通过搜索求解问题有两个步骤,一是形式化目标和问题,二是搜索算法求出行动序列。搜索指的是Agent寻找一组行动序列到达目标的过程,输入是问题,输出是行动序列形式的问题的解。
比如我的另一篇文章中讨论的罗马尼亚问题,问题的形式化需要用五个组成部分来描述,在罗马尼亚问题中:
Status Agent的初始状态:s = In(Arad)
Action Agent的行动集合:a(s) = a(In(Arad)) = {Go(Sibiu), Go(Timisoara), Go(Zerind)}
Result 对每个行动的描述,即转移模型:Result(s, a) = Result(In(Arad), Go(Sibiu)) = In(Sibiu)
初始状态、行动集合、转移模型三者定义了问题的状态空间——从初始状态可以到达的所有状态的集合。
状态空间形成一个有向图,即状态空间图,
结点表示状态,结点之间的边表示行动,
状态空间中的一条路径:通过行动连接起来的一个状态序列,
状态空间中从初始状态到达目标状态的一条路径是问题的一个解。
- 目标测试:可以是一个状态亦可以是一个状态集合,在上述问题中目标状态是{In(Bucharest)},目标检测就是判断当前状态是不是目标状态集合中的状态。
- Cost 路径耗散:c(s, a, s’) = c(In(Arad), Go(Sibiu), In(Sibiu)) = 140
上述五者,即初始状态、行动集合、转移模型、目标测试和路径耗散构成Agent的形式化描述,状态空间中从初始状态到达目标状态的一条路径是问题的一个解,解的质量由路径耗散函数度量,路径耗散值最小的解即为最优解。
1.经典搜索
搜索算法基础
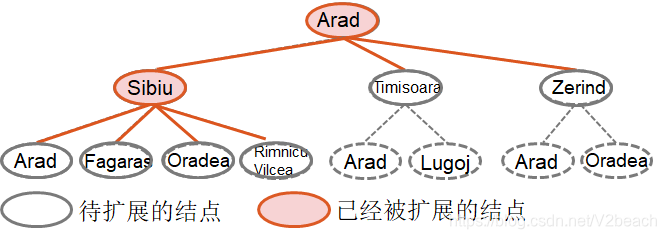
还是用罗马尼亚问题为例,可以看到图上,标红色节点的是已被扩展的节点,标红色的边连接的白色节点则是待扩展的节点。在这里的学习中,已经被扩展的节点集合被称为探索集(closed表),待扩展的节点集合被称为边缘集。
在这里,节点对应的是状态空间中的状态Status,连线代表行动,是行动集合Action(Status)中的一个行动,算法的过程就是不断地在边缘节点中找一个合适的节点进行扩展到达下一个状态,直到找到解或者没有状态能够扩展(无解)为止。
不同算法之间的区别就在于选择边缘集中哪一个新的边缘节点(状态)进行扩展,也叫做不同的搜索策略。
搜索算法性能评价
就像学算法看算法导论一样,人工智能导论也有算法的性能评价,搜索算法的性能评价分别为,
完备性—当问题有解时,算法保证能否找到解;
最优性—搜索策略能否找到最优解,
时间复杂度和空间复杂度就不提了,那个是算法课讨论的内容。

另外,每个内容都要从书上看一个例子。
Ⅰ.无信息搜索
宽度优先搜索
原理是,每次都扩展树上边缘集中深度最浅的节点,直到找到解。宽度优先搜索实现时,将边缘集组织为FIFO队列,可以确保在下一层被扩展之前本层的所有结点都已经被扩展。
这里还有一个考点是,宽度优先和一致代价这里提到了一个目标检测的时间点,宽度优先搜索是节点被生成的时候进行测试。
宽度优先搜索的性能评价,
完备性,当分支因子b有限时,一定能找到目标结点;
最优性,找到的节点一定是深度最浅的节点,如果路径代价是基于节点深度的非递减函数,也就是说不会随着遍历加深,总的路径代价反而变小,那么找到的就是最优解,说白了就是负权边;
时间复杂度,每个状态有b个后继,路径的深度为d,则最坏情况下$O(b^d)$;
空间复杂度,$O(b^d)$。
一致代价搜索
原理是,每次扩展路径消耗)g(n)最小的节点n,是贪婪算法。一致代价搜索实现时,将边缘集组织成按路径消耗值c(s, a, s’)排序的队列。
这里还有一个考点是,宽度优先和一致代价这里提到了一个目标检测的时间点,一致代价搜索是节点被选择扩展的时候进行测试,这个也很好理解,
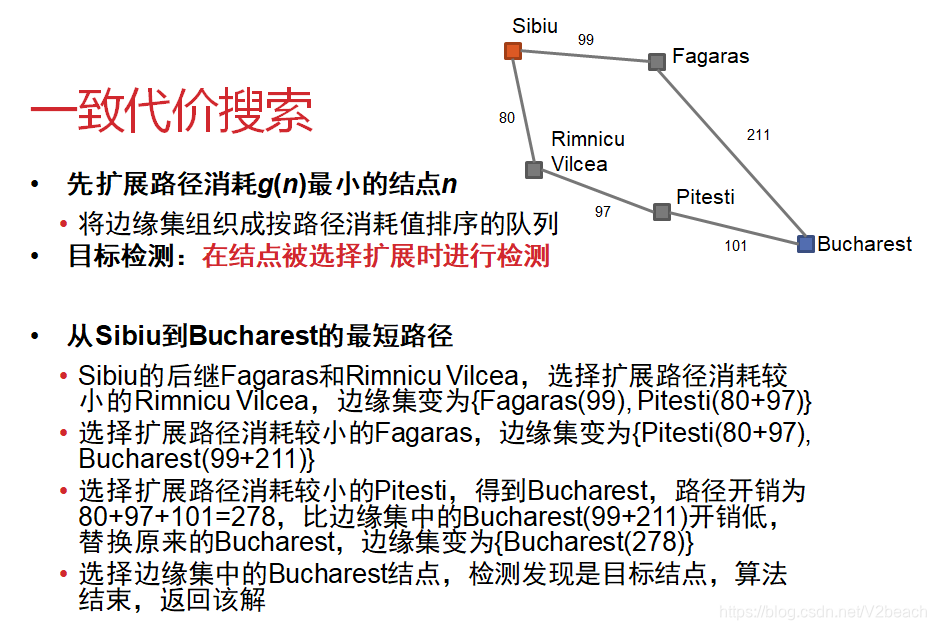
一致代价搜索的性能评价,
深度优先搜索
原理是,每次都扩展边缘集中深度最深的节点,直到找到解。深度优先搜索实现时,将边缘集组织为LIFO栈,可以采用递归实现。
深度优先搜索的性能评价,
完备性,在有限状态空间,避免重复状态和冗余路径的图搜索是完备的,树搜索则不完备,有可能会陷入死循环(如Arad-Sibiu-Arad-…);
最优性,比如我们先搜索左子树的时候,找到解就返回,而最优解可能并不在左子树中;
时间复杂度,$O(b^m)$;
空间复杂度,$O(bm)$。
深度受限搜索
原理是,对深度优先搜索设置最大深度,界限L。
深度受限搜索的性能评价,
优点:避免了深度优先搜索中的无穷路径;
缺点:如果目标结点的深度超过了L,则找不到解,即不完备。
完备性,不完备;
那么最优性当然不满足,最优性是在完备性的基础上扩展的。
时间复杂度,$O(b^L)$;
空间复杂度,$O(bL)$。
迭代加深的深度优先搜索
原理是,在深度受限搜索的基础上,随着深度的加深调整深度界限。
迭代加深的深度优先搜索的性能评价,
当深度界限达到最浅目标结点的深度时,就能找到目标结点。
完备性,当分支因子b有限时是完备的;
最优性,如果路径代价是基于节点深度的非递减函数,也就是说不会随着遍历加深,总的路径代价反而变小,那么找到的就是最优解,说白了就是负权边;
时间复杂度,$O(b^{d})$;
空间复杂度,$O(bd)$。
双向搜索
原理是,从初始状态和目标状态两个方向同时搜索,如果在中间某个结点相遇,则找到解路径。
这个搜索策略的目标检测:两个方向的搜索的边缘集是否有交集,若有交集,则找到解
双向搜索的性能评价,
- 若双向都采用宽度优先搜索,则时间复杂度和空间复杂度都是$O(b^{d/2})$。
Ⅱ.有信息搜索
贪婪最佳优先搜索
原理是,试图扩展离目标最近的结点,评估函数是f(n) = h(n),选择f(n)最小的结点扩展。在罗马尼亚问题中启发函数*h(n)就依然是n*距离目的地Bucharest的直线距离。选择结点扩展时,优先选择h(n)最小的结点。
性能评价,
不完备,有可能会陷入死循环;
不是最优的;
时间复杂度$O(b^m)$,m是搜索空间的最大深度;
空间复杂度$O(b^m)$。
A*搜索
在另一篇文章中已经详细说过了,这里也贴图了。


2.局部搜索
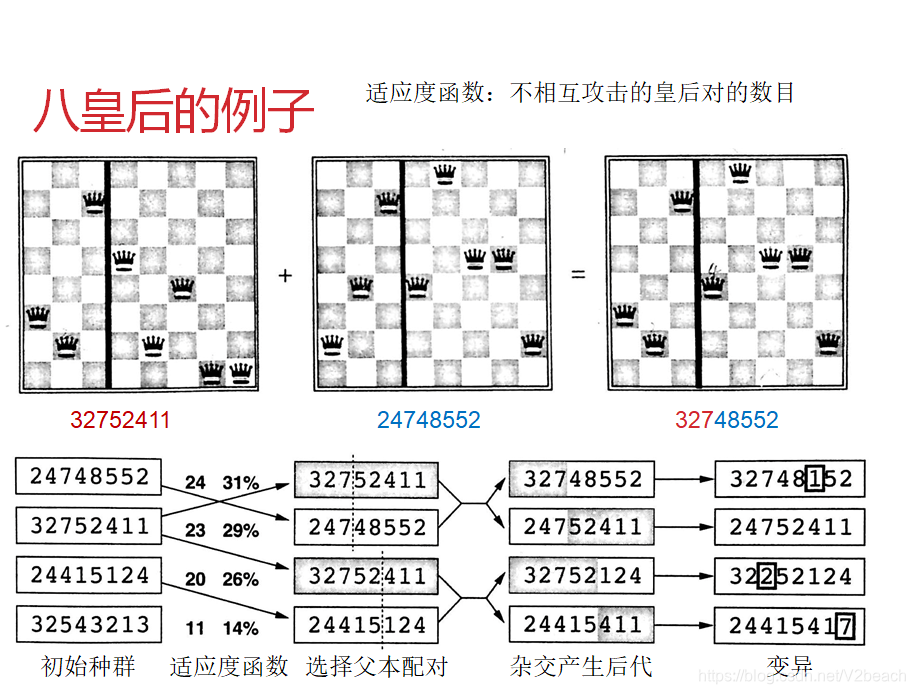
局部搜索关注的是解的状态而不是路径代价,对一个或多个状态进行评价和修改,而不是从初始状态搜索路径,比如八皇后问题,之后的CSP问题也会提八皇后,我的另一篇文章中实现了这里提到的很多算法。
简述
适用问题的特点
- 到达目标的路径不重要,只关注最终状态
局部搜索基本原理
- 从单个结点出发,只移动到它邻接的状态
- 不保留搜索路径
算法优点
- 只使用很少的内存,常数级别
- 能在很大的或无限的状态空间(系统化算法不适用)中找到合理的解
爬山法

模拟退火

局部束

遗传
另一篇文章中以CSP问题为例讨论回溯、最小冲突和遗传算法并给出了具体实现,可以进行参考。

3.对抗搜索/博弈

Ⅰ.形式化

Ⅱ.算法
极小极大算法
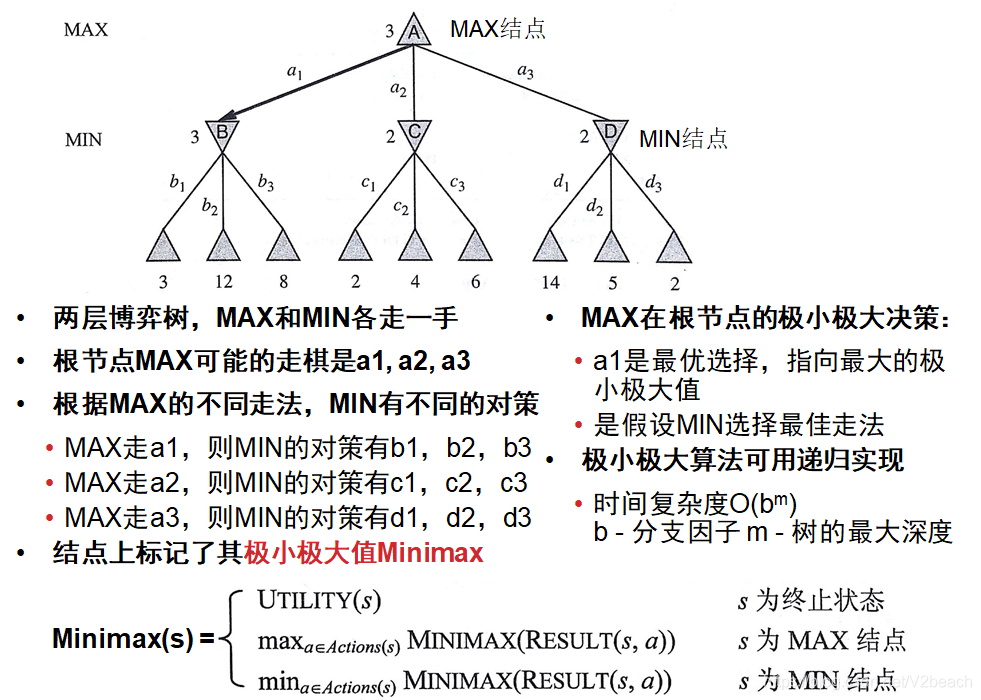
α-β剪枝

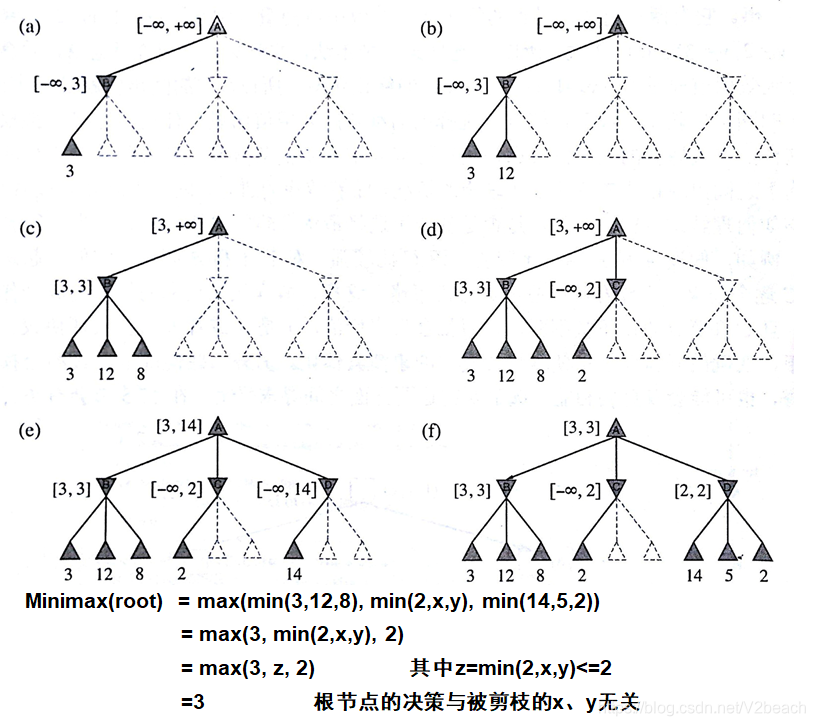
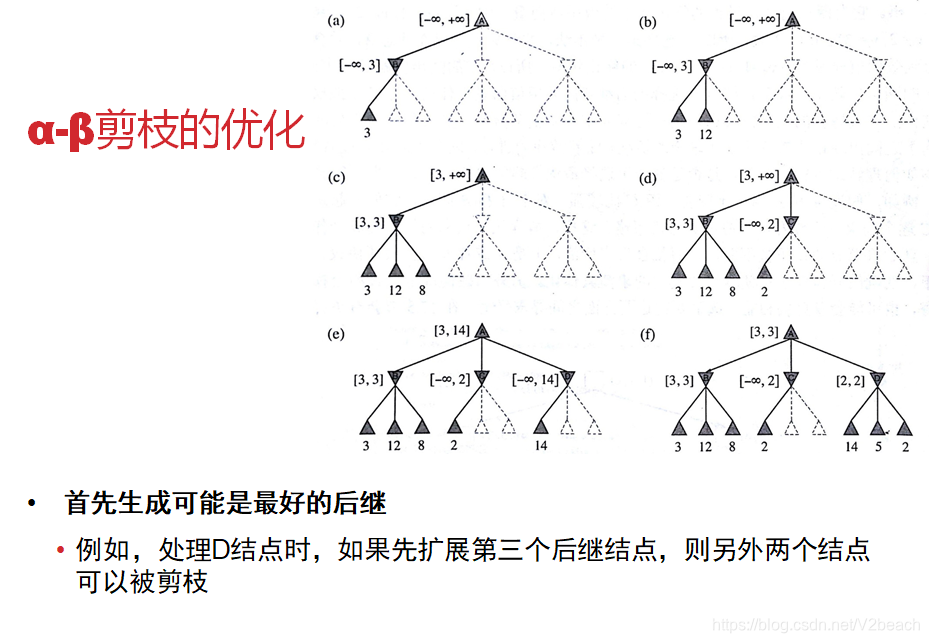
两种算法都可以得到最优招数,但有较高的时间开销,可能无法在合理的时间内决策。
Ⅲ.实施决策优化



4.约束满足问题(CSP)
上面搜索问题的概述中本来应该提到但是没提,搜索问题的形式化主要分为两类,增量形式化和完整状态形式化。
另一篇文章中以CSP问题为例讨论回溯、最小冲突和遗传算法并给出了具体实现,可以进行参考。

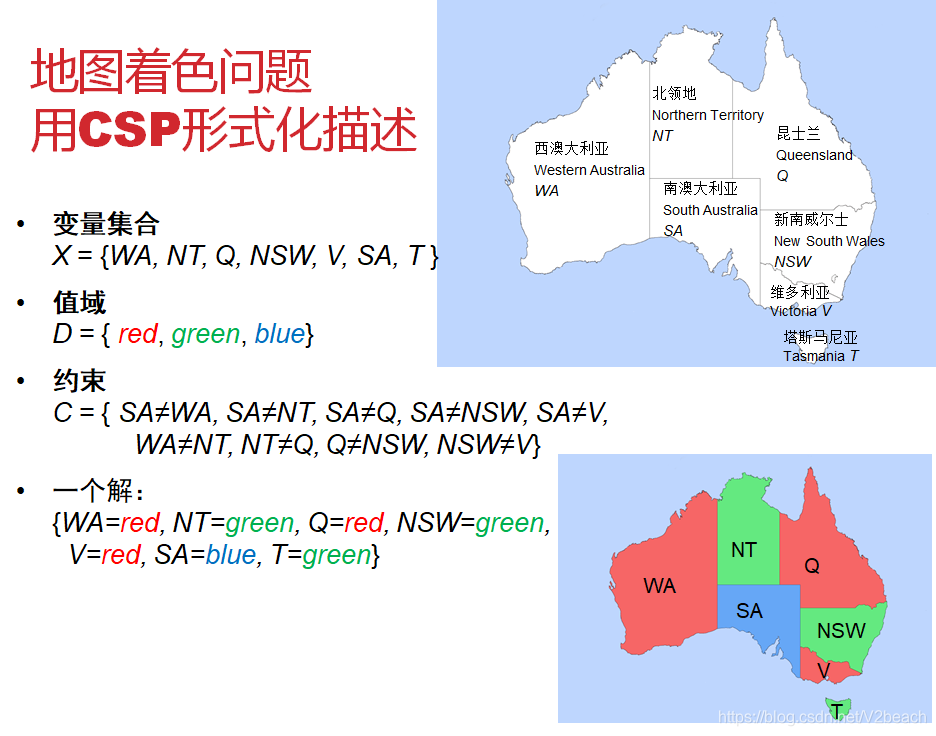
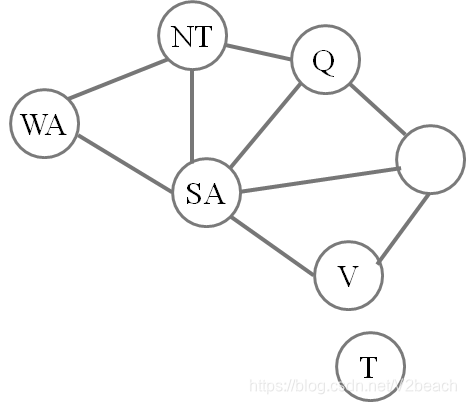
或者像上面一样的约束图也可以表示约束关系。

在回溯算法中,可以这样来赋值。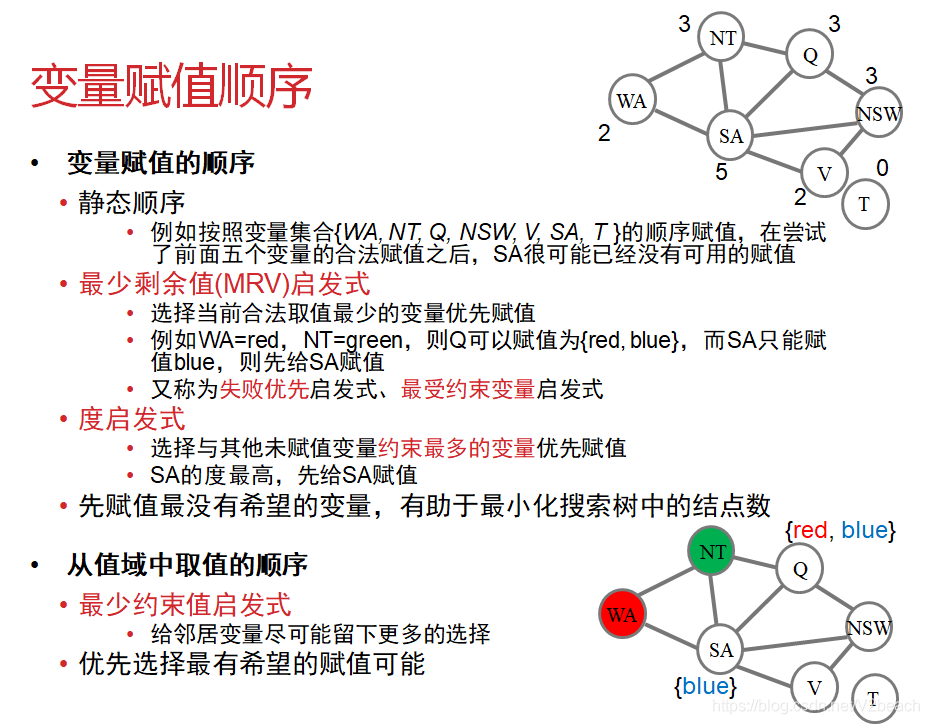
四、机器学习
可能会考一个概念,监督学习、无监督学习和强化学习,怎么准确地描述出来。这里只分析一下监督学习和无监督学习,考到的概率挺大。
监督学习是我们对输入样本经过模型训练后有明确的预期输出,非监督学习就是我们对输入样本经过模型训练后得到什么输出完全没有预期。
监督学习是通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出,例如分类,而无监督学习是直接对数据进行建模,例如聚类。
监督学习是Agent观察某些“输入→输出”样例,学习从输入到输出的映射函数,训练集是带有类标签的,新的数据基于训练集进行分类;无监督学习是Agent学习输入中的模式,训练集是没有类标签的,提供一组属性,然后寻找出训练集中存在的类别或者聚集,新的数据基于聚类算法分出的类别进行归类;强化学习是Agent在强化序列(奖励和惩罚组合的序列)中学习。
1.监督学习
主要是分类问题,解决分类问题的模型也可以用来解决回归问题,比如随机森林构建500棵决策树,每颗决策树有10个叶子节点,也就是10个Label平均值,那么这个随机森林只可能预测出≤5000个可能值,可以说是划分得足够细的分类,达到了回归的效果。
Ⅰ.决策树
决策树是一个树状结构的分类器,用节点和边表示分类过程,以属性描述集合和相应数据作为输入,输出通常是一个分类,中间节点表示对某个属性的测试,叶节点则表示一个类别。分为分类树和回归树,取决于输入的属性是离散还是连续。
决策树例子
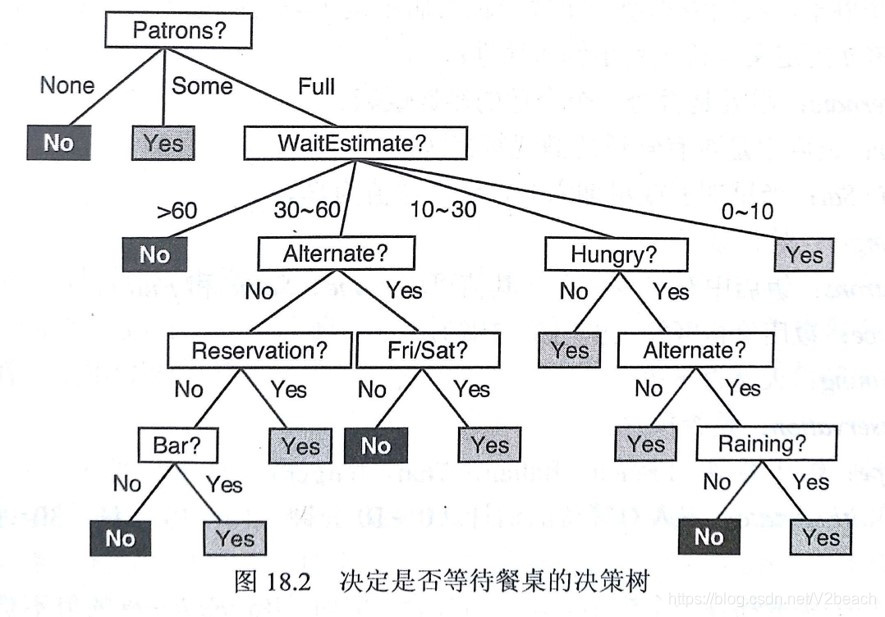
决策树的使用
如何生成决策树是一个重点,下面详细说,先理解生成了怎么用。
使用决策树时,输入是某个实例的属性数据,从根节点开始逐层向下,在根节点及每个中间节点,根据该节点的各条邻接边上采用的划分属性及该实例的该属性取值,选择其中一个分支,直到到达叶节点,就是最终分类了。
像这样通过把实例从根节点根据实例他本身的对应属性和边上的选择属性,排列到某个叶结点来分类实例,就能输出该实例所在的类别。
决策树的生成
总的来说,所有的决策树生成算法都是—决策树生成时,在每个中间节点选一个属性进行划分,根据属性的取值划分为不同的子树,直到不能划分。
算法通常是两个步骤:
- 树的生成
- 全部数据聚集在根节点
- 采用某种算法(宽度优先、递归等)生成树,关键是如何选取下一个属性以及属性如何划分
- 在每个中间节点选择某一个属性进行划分,直到不能继续划分
- 树的修剪
- 去掉一些可能是噪音或者异常的数据
关键是如何选取下一个属性以及属性如何划分,算法的区别主要就在这,另一个关键是确定何时停止划分。除了划分方式和停止时间之外,如何避免监督学习的过拟合也十分关键。下面就讨论这仨问题:
决策树停止生长一般有三种情况,1.当前节点包含的样本已经属于同一个类别了;2.当前属性集空了,能划分的属性都划分完了;3.节点里面所有的样本在所有属性上取值都相同,唯独分类不同,也无法继续划分;4.样本空了,纵使有这个属性也无法划分。
怎么在节点上选择划分哪个属性呢?
树和子树根节点的划分算法,都要让节点随着树生长,其中样本趋于同一类别,即节点的纯度(purity)越来越高。量化纯度的算法有很多,比如ID3 C4.5 CART等算法,
以ID3为例,首先计算出根节点的信息熵,再算出每个属性的信息增益,选信息增益大的作为节点的划分属性,这里我理解的信息增益就是对样本来说区分度最大的属性。C4.5用的是信息增益率,CART用的是基尼值,指的是随机抽取样本类别不一样的概率,基尼指数越小表示纯度越高越适合作为划分属性。总之划分节点选择的属性,找的是划分之后最大限度地减少分类的可能性的那个属性。
过拟合是模型泛化能力差,对训练集拟合度高而预测准确率低的情况,避免过拟合,可以通过剪枝进行优化,也可以通过下一个算法,基于决策树的随机森林进行优化。
剪枝分为预剪枝和后剪枝,分别是划分节点前进行估计预测,当前节点能否提升泛化能力;先生成决策树再Bottom-up地进行考察,如果把当前节点变成叶节点泛化能力可以提升就将子数变成叶节点。
这里偷个懒,贴一下课程ppt的图。
首先预剪枝,划分出训练集和测试集,这里的测试集用来评估精度,事对泛化能力的评估。
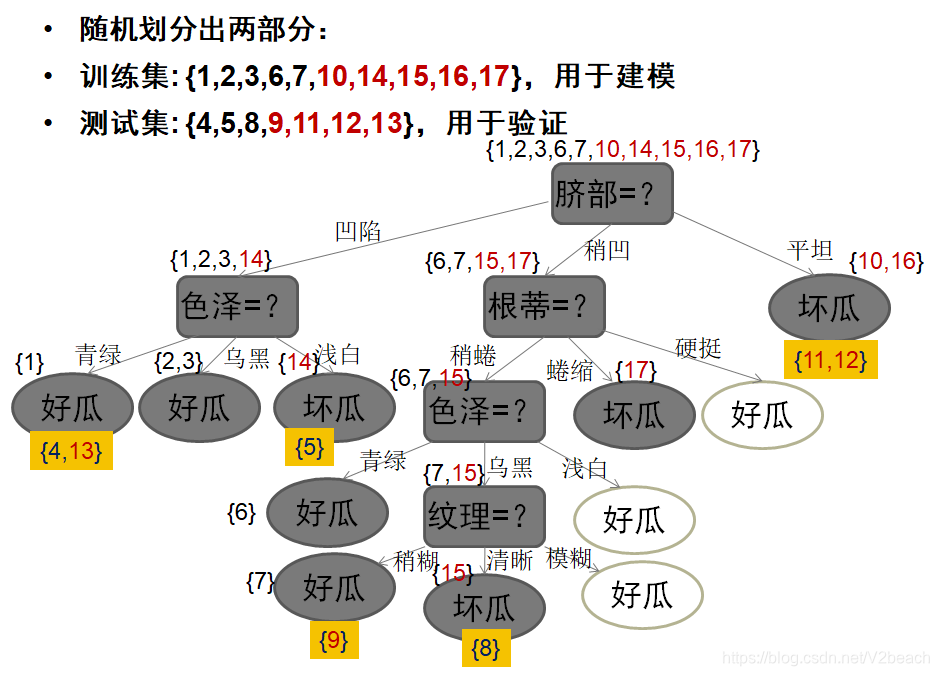
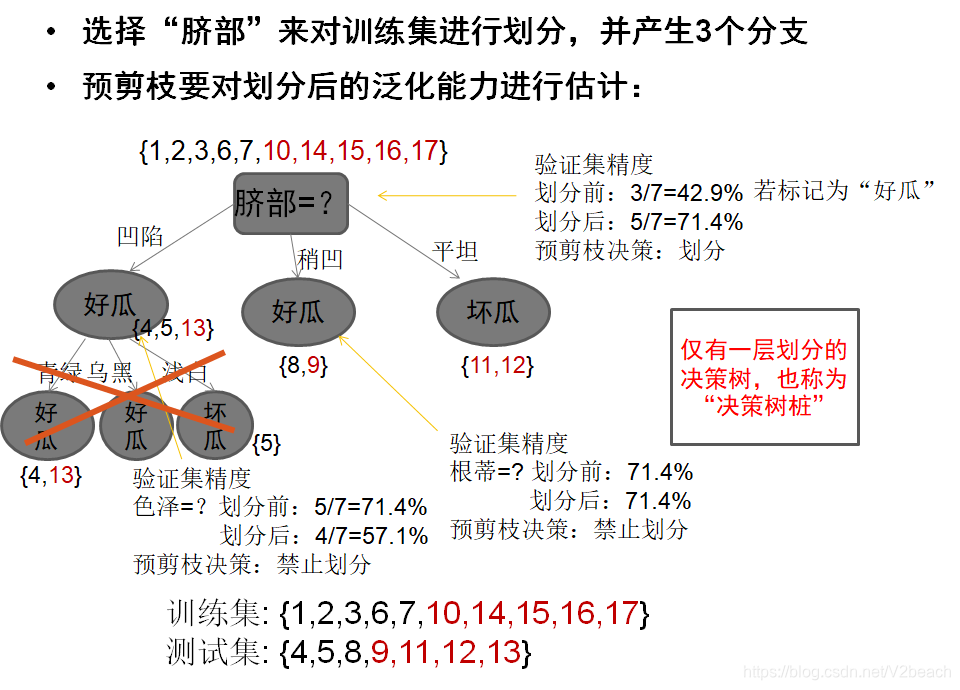
预剪枝的优缺点有,
优点
- 降低了过拟合的风险
- 显著减少了决策树的训练时间开销和预测试时间开销
缺点
- 有些分支的当前划分虽不能提升泛化能力、甚至可能导致泛化性能暂时下降,但在其基础上进行的后续划分却有可能导致性能显著提高
- 预剪枝基于“贪心”,禁止这些分支展开,带来了欠拟合的风险
然后是后剪枝,
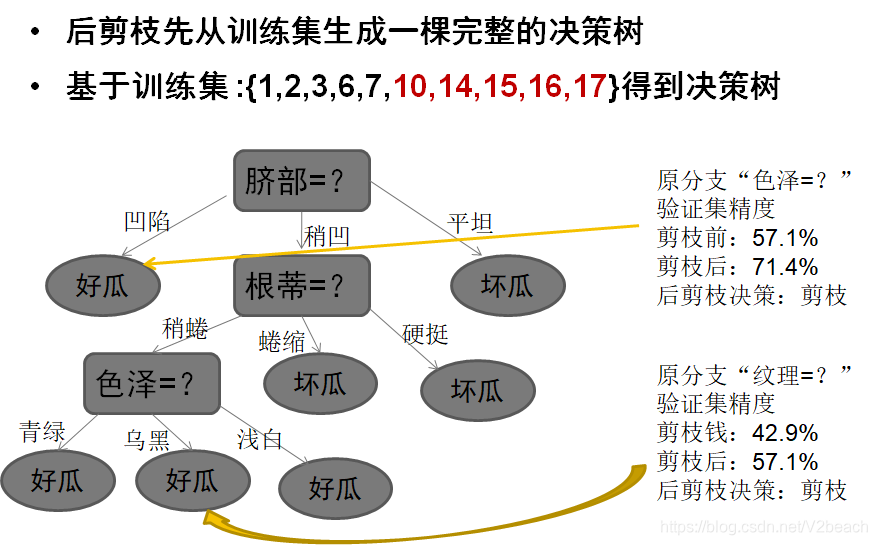
优点
- 欠拟合风险很小,泛化性能往往优于预剪枝决策树
缺点
- 后剪枝过程是在生成完全决策树之后进行的,并且要自底向上对树中的所有非叶节点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大得多
后剪枝决策树通常比预剪枝决策树保留了更多的分支,而预剪枝使得很多分支都没有展开,增加了欠拟合的风险,但是后剪枝的时间开销比预剪枝大得多。
Ⅱ.随机森林
随机森林的算法包含了决策树的生成,一般是CART算法构造。




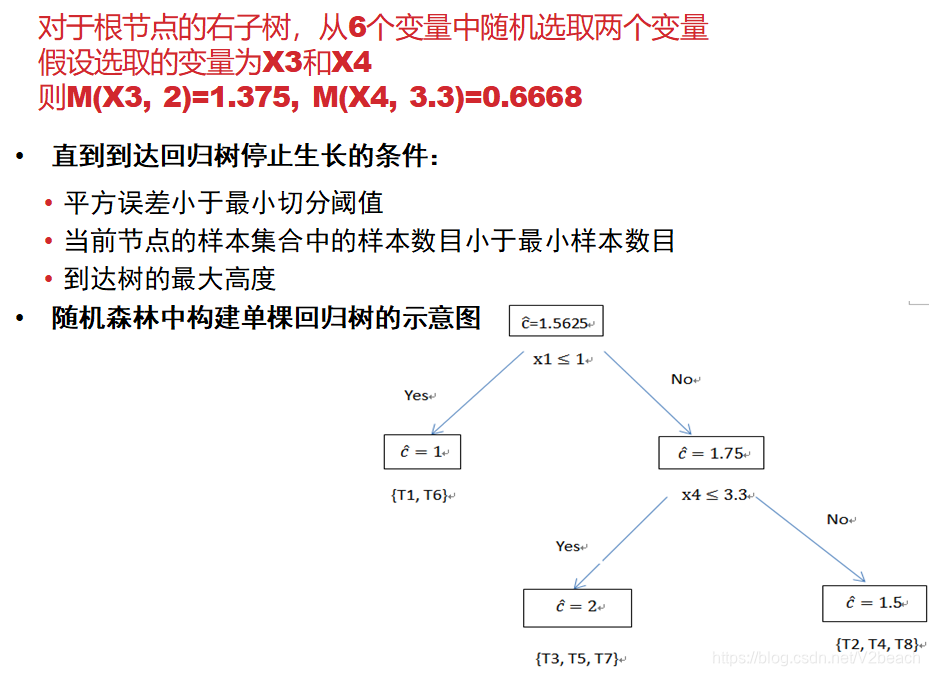

2.无监督学习
主要是聚类问题。
Ⅰ.K-means
一张图就说得非常清楚,K-means应该是cs必须掌握的算法之一,其算法原理大致是,已知K个初始的均值点,也就是要划分K个类的中心点,算法有两个步骤,
- 分配 (Assignment) ,将每个数据点分配到聚类中,直接求点到K个均值点的欧氏距离,距离谁近就分到相应的聚类里面即可;
- 更新(Update) ,上一步得到了新的聚类,对每一个聚类用最小二乘算法求出一个新的均值中心,均值点。
当然初始化、分配、更新都有很多不同的算法,且各有千秋,不多赘述了。
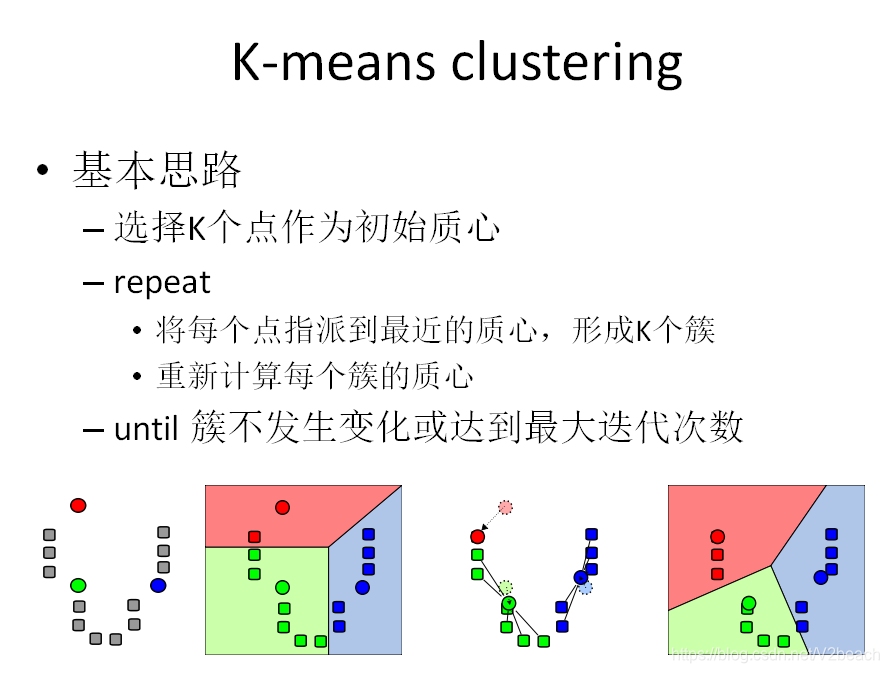
其特点是,
优点
- 对于处理大数据集合,该算法非常高效,且伸缩性较好
缺点
- 要事先确定簇数K
- 对初始聚类中心敏感
- 经常以局部最优结束
- 对噪声和孤立点敏感
适用范围
- 当潜在的簇形状是凸面的,簇与簇之间区别较明显,且簇大小相近时,其聚类结果较理想
- 不适于发现非凸面形状的簇或大小差别很大的簇
Ⅱ.层次聚类
层次聚类(Hierarchical Clustering)是通过计算数据点之间的相似度创造一颗有层次的聚类树,创建层次聚类树常用的是自下而上的合并,原始数据点位于最底层,最后结果应该是下图所示的形式。
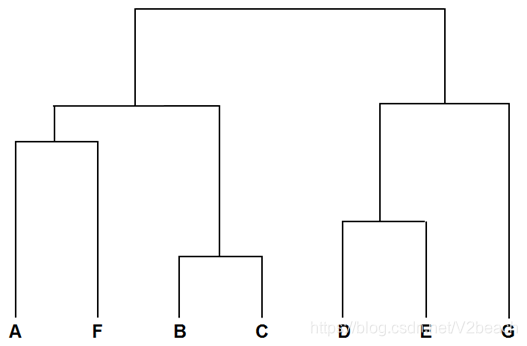
生成的基本步骤是:
计算样本之间的距离,将距离最近的点合并到同一个类
计算类与类之间的距离,将距离最近的类合并为一个大类
不停的合并,直到合成一个类
样本与样本之间的距离可以直接计算坐标系上的欧氏距离,而类与类的距离怎么计算呢?计算方法有
最短距离法:将类与类的距离定义为类与类之间样本的最短距离
最长距离法
中间距离法
类平均法
高概率考点总结
暂时不贴,等考前再贴,或者自己总结完就不发出来了。